【Arduino】DMX512制御
DMX512制御をArduinoで実装してみたので、備忘録を残しておく。
DMX512とは
DMX512、通称「DMX」はライブやコンサート、イベントなどの舞台演出に使われる照明機器を制御する通信規格である。DMX512は「Digital Multiplex with 512 pieces of Information」の略である。現在の最新の仕様書は「E1.11, USITT DMX512–A」または単に 「DMX512-A」とも呼ばれ、ESTA(Entertainment Services and Technology Association)が保守している。
DMX512は制御信号を送信するコントローラとその信号を受け取る制御機器で構成される。通信は常にコントローラからの一方通行でコントローラ以外の制御機器が自ら制御信号を送信することはない。コントローラと制御機器はデイジーチェーン(数珠繋ぎ)方式で接続され、制御機器は原則としてDMX-INとDMX-OUTの端子を搭載し、スルーアウト(ブリッジ出力)で入力された制御信号を次の機器のためにそのまま出力する。デイジーチェーンの最後に接続された制御機器の出力側に、ターミネータ(終端抵抗)を接続する必要がある。制御信号は、1本のケーブルで512チャンネルを送信でき、各チャンネルの信号は256段階で制御可能である。
仕様
- DMX512-Aの通信速度は250kbpsである
- シールド付きツイストペアケーブルを使用する
- 最大ケーブル長400m(250kbpsの通信速度を保証できる最大長。RS-485の仕様では1500mまでの通信が保証されている。)
- 1台のマスターに最大32台のスレーブを接続可能
- 末端には120Ωのターミネータ(終端抵抗)を接続する
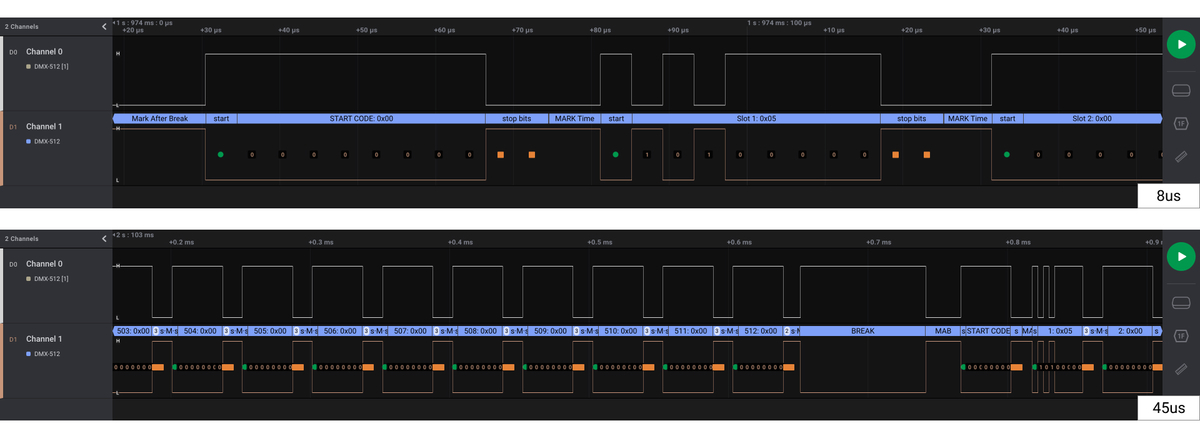
パケット仕様

実際にロジアナで確認したところ、512個のスロットが流れていることを確認することができた。
DMX Shield for Arduino
Arduinoの上にこのDMXシールドを追加するだけで、簡単にDMX512制御が可能になる。めちゃくちゃ便利なシールド。(DFRobotに感謝しかない。)

仕様
- Arduino用シールド(拡張ボード)
- NEUTRIK XLR 3pin コネクタ(オス1 / メス1)
- MAX485モジュールを搭載
オンボードジャンパの設定
DMX Shield for Arduinoには4つのジャンパーが実装されている。
| ラベル | 機能 |
|---|---|
| EN / ^EN | Shieldの有効・無効の切り替え(ハードウェアシリアルをShieldが使う・Arduinoのプログラム書き込みが使う) |
| DE / Slave | DMXマスター・スレーブ切り替え |
| TX-uart / TX-io | TX:UART(D1)とD4の切り替え |
| RX-uart / RX-io | RX:UART(D0)とD3の切り替え |

Since the library uses the Arduino's primary USART it is not possible to use it together with the Hardware Serial libraries in your project since that will cause conflicting ISR (Interrupt service routine) routines.
DMX Library for Arduino Wiki%20routines.)
Shieldの有効・無効の切り替えが実装されている理由としては、DMX Shield for ArduinoのDMX通信時にArduinoのハードウェアシリアルを使用していることが挙げられる。Arduino UNOにプログラムを書き込む際にもハードウェアシリアルを使うため、DMX Shield for Arduinoが有効になっている場合には、コンフリクトが発生してしまい、プログラムを書き込むことができない。そのため、プログラムを書き込む際には、DMX Shield for Arduinoを無効にする必要がある。
また、TX / RXポートの切り替えに関しては、Arduino unoはハードウェアシリアルのポートを1ポートしか持たないので、UART(D0/D1)を選択するしかない。
ライブラリ
DMX Shield for Arduinoを使うためのライブラリは以下からダウンロードすることができる。
Conceptinetics.zipのzipファイルを解凍し、Arduino IDEの libraries フォルダ内に配置する。(Macの場合、~/Documents/Arduino/libraries/)
もしくは、Arduino IDEを開き、スケッチ > ライブラリをインクルード > .ZIP形式のライブラリをインストール... から、zipファイルをアップロードする。
DMX Shield for Arduino の実装
基本的には、ライブラリを使ってそのまま実装を行った。
DMX Master Sample Code
このサンプルコードでは、以下が実装されている。
- DMXマスターとして1-100チャンネルを操作可能
- MAX485の読み取りと書き込みの制御コントロールはD2を設定
- チャンネル2-50に対して、値127を設定
- チャンネル1に100msごとに1ずつインクリメントした値を設定(値がMAXの255になると、再度0に戻る)
#include <Conceptinetics.h> // The master will control 100 Channels (1-100) // depending on the ammount of memory you have free you can choose to enlarge or schrink the ammount of channels (minimum is 1) #define DMX_MASTER_CHANNELS 100 // Pin number to change read or write mode on the shield #define RXEN_PIN 2 // Configure a DMX master controller, the master controller will use the RXEN_PIN to control its write operation on the bus DMX_Master dmx_master(DMX_MASTER_CHANNELS, RXEN_PIN); // the setup routine runs once when you press reset: void setup() { // Enable DMX master interface and start transmitting dmx_master.enable(); // Set channel 2 - 50 @ 50%(255 / 2 = 127) dmx_master.setChannelRange(2, 50, 127); } // the loop routine runs over and over again forever: void loop() { static int dimmer_val; // Keep fading channel 1 in from 0 to 100% dmx_master.setChannelValue(1, dimmer_val++); if (dimmer_val == 255) { dimmer_val = 0; } delay (100); }
DMX Slave Sample Code
このサンプルコードでは、以下が実装されている。
- DMXスレーブとして10チャンネルを操作可能
- MAX485の読み取りと書き込みの制御コントロールはD2を設定
- スタートアドレスをチャンネル1に設定(すなわち、1-10までの値を読み取る)
- スタートアドレスのチャンネル(今回の場合、1チャンネル)の値を取得し、変更があればPCに出力する
Arduino unoを使うのであれば、ハードウェアシリアルはPCとの接続用として使用し、状況のモニタリングを行いたかった。しかしながら、DMX Shield for Arduinoのハードウェアシリアルとコンフリクトするので使用できない。そのため、Arduino UNO + DMX Shield for Arduinoの場合、PCとのシリアル通信は、IOポートを利用したSoftwareSerialを使う必要があった。
#include <Conceptinetics.h> #include "SoftwareSerial.h" // The slave device will use a block of 10 channels counting from its start address. // If the start address is for example 56, then the channels kept by the dmx_slave object is channel 56-66 #define DMX_SLAVE_CHANNELS 10 // Pin number to change read or write mode on the shield #define RXEN_PIN 2 // Configure a DMX slave controller DMX_Slave dmx_slave(DMX_SLAVE_CHANNELS, RXEN_PIN); // Global variables uint8_t channel_value = 0; // Configure SoftwareSerial SoftwareSerial DebugSerial(4, 5); // RX, TX // the setup routine runs once when you press reset: void setup() { // Enable DMX slave interface and start recording DMX data dmx_slave.enable(); // Set start address to 1, this is also the default setting // You can change this address at any time during the program dmx_slave.setStartAddress(1); // setup software serial for PC DebugSerial.begin(9600); delay(500); DebugSerial.println("ProgramStart"); } // the loop routine runs over and over again forever: void loop() { uint8_t value = dmx_slave.getChannelValue(1); if (channel_value != value) { DebugSerial.print("Channel Value: "); DebugSerial.println(value); } }
まとめ
無事にArduinoでDMX512制御を思い通りに実装することができた。
記憶階層・キャッシュ
現在、CSの勉強のために、コンピュータアーキテクチャ (電子情報通信レクチャーシリーズ)を読んでいる。
これまでパイプラインなどを通して制御の流れに着目してきた。今回は記憶装置であるメモリに焦点を当てる。
命令パイプラインとメモリ
 上図のパイプラインにおいて、命令メモリからの命令のフェッチと、データメモリへの読み書きが同じ1クロックで行われている。
上図のパイプラインにおいて、命令メモリからの命令のフェッチと、データメモリへの読み書きが同じ1クロックで行われている。
メモリはレジスタと異なり、アクセスに時間がかかる。メモリへのアクセス時間が長くなる場合、全体のスループットは最も長いステージの処理時間で決定されるので、メモリへのアクセス時間の短縮が大きな課題となる。
- 理想的なメモリ
- 容量は無限大の大容量
- アクセス時間は最短で高速アクセス
- 単純なアドレシングでアクセスできる
- 現実のメモリ
- 大容量と高速アクセスは両立しない(容量が大きくなればなるほど、アクセス時間が長くなってしまう。)
上記に示すように、メモリの理想と現実には乖離がある。そのため、「高速小容量のメモリ」と「低速大容量のメモリ」を組み合わせる、記憶階層を用いることで実質的に「高速大容量メモリ」の機能を実現する。
記憶階層
 記憶システムは、上図のような階層構造をとる。すなわち、CPUに近い方のレベルをその下のレベルの部分集合とする。一番下のレベルには全てのデータを格納する。CPUに近い方のレベルを上位レベルといい、CPUから遠い方のレベルを下位レベルという。上位レベルのメモリは下位レベルのメモリよりも小さくて高速である。両レベル間で取り交わすデータの最小単位をブロックまたはラインと呼ぶ。下位レベルのメモリでよく使われる命令やデータを上位のメモリにコピー(データ転送)しておく。CPUから取り出しの命令があった場合には、まず上位のメモリを調べてそこにデータがあればそのデータをCPUに取り出す。
記憶システムは、上図のような階層構造をとる。すなわち、CPUに近い方のレベルをその下のレベルの部分集合とする。一番下のレベルには全てのデータを格納する。CPUに近い方のレベルを上位レベルといい、CPUから遠い方のレベルを下位レベルという。上位レベルのメモリは下位レベルのメモリよりも小さくて高速である。両レベル間で取り交わすデータの最小単位をブロックまたはラインと呼ぶ。下位レベルのメモリでよく使われる命令やデータを上位のメモリにコピー(データ転送)しておく。CPUから取り出しの命令があった場合には、まず上位のメモリを調べてそこにデータがあればそのデータをCPUに取り出す。
- レジスタ:CPU内部にある、演算や実行状態の保持に用いる記憶装置。
- キャッシュメモリ(L1, L2):主記憶装置より高速にアクセス可能な記憶装置。使用頻度の高いデータや命令を保持しておくことで、相対的に低速な主記憶装置へのアクセスを減らすことができ、処理を高速化することができる。
- 主記憶装置(メインメモリ、RAM):CPUの命令によって直接読み書きが可能な記憶装置。実行中の命令やデータを保持しておく。
- ディスクキャッシュ:補助記憶装置より高速にアクセス可能な記憶装置。キャッシュメモリ同様に、使用頻度の高いデータを複製して格納しておくことで、処理を高速化することができる。
- 補助記憶装装置:ハードディスク、フラッシュメモリなどの記憶装置。
局所性
記憶階層がアクセス時間の短縮(高速化)に有効なのは、命令やデータに局所性(locality)があるためである。
- 空間局所性(Spacial Locality)
- あるロケーションにあるデータが参照されると、そのアドレスの近傍にあるデータが間もなく参照される傾向がある、という局所性の法則
- 通常プログラムの上から下に順番に実行される、命令アクセス
- 配列要素の逐次アクセス
- 入れ子構造の引数、ローカル変数など
- 時間局所性(Temporal Locality)
記憶階層と機械語プログラム
メモリには各階層があり、それぞれにアドレスが存在し、各階層間でデータのやり取り(データ転送、読み取り、書き込み)が発生する。この記憶階層を意識して、最良のメモリの利用方法を考えて、全てプログラムするのはかなり骨が折れる作業である。プログラマとしては、高速で大容量のメモリが一つだけあるものとしてプログラムを書き、ハードウェアの機構でどの階層のメモリをどう使って局所性を活かすかを決めることが望ましい。
単純に命令セットだけを意識してプログラムを書いておけば、効率や安全性はハードウェアが勝手に面倒を見てくれる。この性質を透過性(transparency)と呼ぶ。
キャッシュメモリ
キャッシュメモリは、レジスタと主記憶装置との間にあるメモリである。

- CPUが主記憶装置からデータを読み込もうとする。
- キャッシュメモリにデータがないので、主記憶装置からデータをキャッシュメモリに転送する。この際、必要なデータのみでなく、空間的局所性を考慮して、まとまった単位でデータ転送を行う。
- キャッシュメモリからCPUにデータが読み出される。
- 再度、同じデータを読み込もうとした際には、すでにキャッシュメモリにデータがあるので、主記憶装置にアクセスすることなく、キャッシュメモリのみが参照されデータが読み出される。
用語整理
- ヒット:CPUから要求されたデータが上位レベルのどこかのブロックの中に存在すること
- ミス:上位レベルのどこにも求めるデータが見つからないこと
- ヒット率:記憶階層のあるレベルでメモリへのアクセスがヒットする割合。記憶階層の性能の測定値として使われることが多い。
- ミス率:記憶階層のあるレベルでメモリへのアクセスがヒットしない割合。1-(ヒット率)で求めることができる。
- ヒット時間:記憶階層のあるレベルにアクセスするのに要する時間。この時間にはアクセスがヒットするかミスするかの判定に必要な時間を含む。
- ミス・ペナルティ:記憶階層のあるレベルでキャッシュ・ミスが発生したときに、その下位のレベルからブロックを取り出すのにかかる時間。該当のブロックにアクセスし、それを記憶階層間で転送し、 該当のレベルに収め、ブロックを要求元に引き渡すのにかかる時間が含まれる。

次に、複数のデータを参照し、キャッシュメモリがいっぱいになった場合を考える。
- キャッシュメモリにないデータの読み出し命令があり、主記憶装置からキャッシュメモリにデータを転送しようとした場合に、キャッシュメモリにデータが入らない場合、衝突が発生する。
- 衝突が発生すると、古いデータがキャッシュから追い出される。(追い出し)
- キャッシュメモリの空いたメモリに、新しいデータが転送される。(再コピー)
衝突が発生した場合に、主記憶装置へのデータ転送(書き戻し)を行う必要があるか否かは、CPUの書き込み命令(store)の対応方法によって決定される。
ライトスルー方式とライトバック方式
キャッシュメモリは主記憶装置のデータをコピーしているので、データの読み出し命令(load)に対して主記憶装置の操作は不要である。しかしながら、データの書き込み命令(store)に対しては、新しいデータを主記憶装置にも書き込む必要がある。この書き戻しのタイミングによって、以下の2つに分類される。

- ライトスルー方式(write through)
- ストア命令がくる度に、キャッシュメモリだけでなく、主記憶装置にもデータを書き込む。
- 主記憶装置はキャッシュの10倍以上は遅いので、実行効率が落ちる。
- 主記憶装置への書き込み速度の問題は、ライトバッファ(write buffer)と呼ばれる高速のメモリを別途設けることで解決するのが一般的である。
- キャッシュから追い出される際のメモリへの書き戻しが不要。よって、新たにキャッシュラインを主記憶装置から読み出す時のコストが低い。
- ストア命令がくる度に、キャッシュメモリだけでなく、主記憶装置にもデータを書き込む。
- ライトバック方式(write back)
キャッシュのマッピング
キャッシュのブロックをどのようにキャッシュメモリに配置するかで、以下の3つの方式がある。
- ダイレクトマップ方式
- あるインデックスに対して一意にラインのキャッシュの位置が決まる
- フルアソシアティブ方式
- インデックスが存在せず、全てのキャッシュラインのタグと比較する
- セットアソシアティブ方式
ダイレクトマップ方式
 ダイレクトマップ方式では、あるインデックスに対して一意にラインのキャッシュの位置が決まる。キャッシュ上の位置が特定されても、ここにあるキャッシュラインが求めるものかどうかは以下の条件を満たす必要がある。
ダイレクトマップ方式では、あるインデックスに対して一意にラインのキャッシュの位置が決まる。キャッシュ上の位置が特定されても、ここにあるキャッシュラインが求めるものかどうかは以下の条件を満たす必要がある。
また、キャッシュラインの大きさが4語なので、キャッシュライン内オフセットの2ビット(00, 01, 10, 11)を使用しMUXに入力し、キャッシュラインからいずれか一つのデータ語を選択する。ただし、MIPSアーキテクチャでは、各アドレスの最下位2ビットは語内のバイト・オフセット指定に使用される。そのため、最下位2ビットをキャッシュラインの選択用に使用することはできない。
もしタグが等しくない場合は、キャッシュミス(cache miss)が起こったという。キャッシュミスが起こった場合は、アクセスしているキャッシュラインを、タグとインデックスの値を見て主記憶装置に書き戻し、代わりに求めるキャッシュラインを主記憶装置からキャッシュメモリに読み出す。
キャッシュミス(3C)
キャッシュミスには、以下の3種類があり、「三つのC」と呼ばれることもある。
- 初期参照ミス(compulsory miss, cold start miss)
- まだキャッシュに読み込まれていないキャッシュラインを最初にアクセスした時に発生するミス
- コールド・スタート・ミスとも呼ぶ
- [対策]キャッシュラインの大きさを大きくする
- キャッシュラインの数が減るので、初期参照の数が少なくなる
- 空間的局所性に起因するミス率が低下する
- キャッシュラインを大きくしすぎると、ミスが発生した場合のペナルティが大きくなり、性能低下に繋がる可能性がある
- 競合性ミス(conflict miss, collision miss)
- 同じインデックスを持つ異なるキャッシュラインにアクセスすることで起こるミス
- コリジョン・ミスとも呼ぶ
- [対策]連想度を上げることで競合性ミスは軽減される
- 連想度とは任意のインデックスで複数のキャッシュラインの集合にアクセスできる場合のラインの数である
- 連想度を上げることでアクセス速度が遅くなるので、全体的な性能の低下を招く可能性がある
- 容量性ミス(capacity miss)
キャッシュミスが発生すると、CPUでの演算の実行を一時止め、メモリとキャッシュの間でキャッシュラインの交換をしてから実行を再開することになる。
フルアソシアティブ方式
 フルアソシアティブ方式には、インデックスは存在せず、参照されるごとに全てのキャッシュラインのタグがメモリアドレス内のタグと比較される。どれか一つのタグが等しければヒットであり、対応するラインの語が読み出される。一致するタグがない場合、キャッシュメモリの空いている任意の場所に主記憶装置からキャッシュラインが読み込まれ、その上で読み書きが行われる。
フルアソシアティブ方式には、インデックスは存在せず、参照されるごとに全てのキャッシュラインのタグがメモリアドレス内のタグと比較される。どれか一つのタグが等しければヒットであり、対応するラインの語が読み出される。一致するタグがない場合、キャッシュメモリの空いている任意の場所に主記憶装置からキャッシュラインが読み込まれ、その上で読み書きが行われる。
メリット
- インデックスが存在しないので、競合性ミスは発生しない。
デメリット
- キャッシュ上のタグの容量が大きくなり、タグ比較などの回路が膨大になってしまい、ハードウェアのコストが増大する。
- すべてのキャッシュラインを検索するので、ゲート遅延が大きくなり、パイプライン動作時のクロックの長さを伸ばしてしまう可能性が高い。
以上のことから、フルアソシアティブ方式は小規模のキャッシュに用いられることが多い。
セットアソシアティブ方式
 セットアソシアティブ方式は、ダイレクトマップ形キャッシュでインデックスの指す先に複数のキャッシュラインを格納するものである。一つのインデックスに対応するキャッシュラインの集合をセットと呼ぶ。セットの大きさを"A"とするとき、Aを連想度(associativity)と言い、このキャッシュをAウェイ・セットアソシアティブ形のキャッシュと呼ぶ。上図の場合は、1つのインデックスで2つのキャッシュラインを指し示すので、2ウェイ・セットアソシアティブ形キャッシュである。
セットアソシアティブ方式は、ダイレクトマップ形キャッシュでインデックスの指す先に複数のキャッシュラインを格納するものである。一つのインデックスに対応するキャッシュラインの集合をセットと呼ぶ。セットの大きさを"A"とするとき、Aを連想度(associativity)と言い、このキャッシュをAウェイ・セットアソシアティブ形のキャッシュと呼ぶ。上図の場合は、1つのインデックスで2つのキャッシュラインを指し示すので、2ウェイ・セットアソシアティブ形キャッシュである。
セットアソシアティブ方式は、フルアソシアティブ方式と比較して、タグ比較回路などの回路が小さくてすみ、ゲート遅延も小さい。また、ダイレクトマップ方式と比較して、整合性ミスが少なくなる。
# (ライン数) = (セット数) × (連想度) L = S × A # ダイレクトマップ方式 A = 1 # フルアソシアティブ方式 A = L
キャッシュの入ったCPU
これまでメモリで実装していた部分にキャッシュメモリを追加する。一般的に命令用のキャッシュとデータ用のキャッシュは別々に設ける。
- 命令キャッシュ(instruction cache)
- 読み出しのみ
- 書き込みを行わないため、書き戻しの機構が不要
- データキャッシュ(data cache)
- 読み出しと書き込みの両方を行う
別々に分ける理由は、パイプライン動作時に命令フェッチとデータのロード・ストアの間でキャッシュアクセスの競合を発生させないためである。


まとめ
Webブラウザのキャッシュはなんとなく理解できていたが、今回CPUのキャッシュメモリに関して整理することができた。
| ダイレクトマップ | セットアソシアティブ | フルアソシアティブ | |
|---|---|---|---|
| 連想度 | 1 | A(2,4,..) | =ライン数 |
| セット数 | =ライン数 | S | 1 |
| ハードウェア | 少 | 中 | 多 |
| ゲート遅延 | 小 | 中 | 大 |
| 競合性ミス | 多 | 少 | なし |
関連書籍
")

ビット演算
マイコンのレジスタ操作などをC/C++で行おうと思った場合には、ビット演算が必須となる。ビット演算は論理演算であることを理解していたものの、実際にどのように使うのか理解できていなかったので、今回備忘録として残しておく。
ビットとは
マイコンをはじめとするコンピュータの世界はデジタル、二進数、すなわち「0」か「1」で表現される。コンピュータの世界では1つの「0」か「1」のデータを1ビットと呼ぶ。そして、1ビットを8つ組み合わせたものを1バイトと呼ぶ。
1 Byte = 8 bit
C言語では、二進数を表現する場合、先頭に0bをつける。十進数である「23」を1バイトの二進数で表現すると以下のようになる。
23 = 0b00010111
ビット演算
論理演算は以下のようになっている。

AND
C言語では、AND演算を&で表現する。
#include <iostream> #include <bitset> using namespace std; int main() { int a = 0b10101010; int b = 0b11110000; cout << bitset<8>(a & b) << endl; // 0b10100000 }
- 両方が「1」の場合のみ「1」
- それ以外は「0」
OR
C言語では、OR演算を|で表現する。
#include <iostream> #include <bitset> using namespace std; int main() { int a = 0b10101010; int b = 0b11110000; cout << bitset<8>(a | b) << endl; // 0b11111010 }
- 両方が「0」の場合のみ「0」
- それ以外は「1」(いずれかが「1」であれば「1」)
NOT
C言語では、NOT演算を~で表現する。
#include <iostream> #include <bitset> using namespace std; int main() { int a = 0b10101010; cout << bitset<8>(~a) << endl; // 0b01010101 }
- 「0」と「1」を反転させる
XOR
C言語では、XOR演算を^で表現する。
#include <iostream> #include <bitset> using namespace std; int main() { int a = 0b10101010; int b = 0b11110000; cout << bitset<8>(a ^ b) << endl; // 0b01011010 }
- 「0」と「1」の場合に「1」(両方が一致していなければ「1」)
- 両方が「0」または「1」の場合に「0」(両方が一致していれば「0」)
レジスタ操作
レジスタ操作時に、8bitのレジスタ全てを上書きする場合は直接8bitを指定するだけでいい。しかしながら、現在のレジスタの内1bitのみを書き換えたりする場合、ビット演算を行う必要がある。
実際に具体的な操作対象がある方がわかりやすいので、Arduino UNOのレジスタ操作を実際にやってみる。 デフォルトで入っているExampleのBlinkのコードは、以下のようになっている。
// LED_BUILTIN is D13 for Arduino UNO // the setup function runs once when you press reset or power the board void setup() { // initialize digital pin LED_BUILTIN as an output. pinMode(LED_BUILTIN, OUTPUT); } // the loop function runs over and over again forever void loop() { digitalWrite(LED_BUILTIN, HIGH); // turn the LED on (HIGH is the voltage level) delay(1000); // wait for a second digitalWrite(LED_BUILTIN, LOW); // turn the LED off by making the voltage LOW delay(1000); // wait for a second }
上記のコードをレジスタ操作のみに書き換えてみる。
- Arduino UNO Schematicから、Arduino UNOの13ピンはATMEGA8のPB5(SCK)に繋がっていることがわかる。
- ATmega8 DatasheetでPB5(SCK)のレジスタを確認する。
 PB5、すなわちPORTB5の含まれるレジスタは以下の3種類である。
PB5、すなわちPORTB5の含まれるレジスタは以下の3種類である。
以上のことから、
- PORTB5をOUTPUTに設定したい場合は、DDRBの5bit目を「1」にする。
- PORTB5をHIGHに設定したい場合は、PORTBの5bit目を「1」にする。
- PORTB5をLOWに設定したい場合は、PORTBの5bit目を「0」にする。
void setup() { DDRB = 0b00100000; } void loop() { PORTB = 0b00100000; delay(1000); // wait for a second PORTB = 0b00000000; delay(1000); // wait for a second }
上記の実装の場合、現在のレジスタの状況が何であっても強制的に上書きしてしまっている。特定のビットのみを「0→1」、「1→0」に変更する場合はビット演算を行う。
特定のビットのみをHIGHにしたい場合
特定のビットのみを1にした値と、現在の値でOR | をとる
#include <iostream> #include <bitset> using namespace std; int main() { int PORTB = 0b00010101; cout << "現在の値:" << bitset<8>(PORTB) << endl; int BIT_FLAG = 1<<5; cout << "操作対象:" << bitset<8>(BIT_FLAG) << endl; PORTB |= BIT_FLAG; cout << "計算結果:" << bitset<8>(PORTB) << endl; } // 現在の値:00010101 // 操作対象:00100000 // 計算結果:00110101
a 番目のビットのみを1にした値は (1<<a) で表せる。特定のビットが「1」になっていることをフラグが立っている状態と呼ぶ。よって、
1を二進数表示すると、1 = 0b00000001である。この1ビット目の「1」を任意のビットの位置まで左にシフトすることで特定のビットのフラグが立っている状態を作ることができる。
- 1<<0 = 0b00000001
- 1<<1 = 0b00000010
- 1<<7 = 0b10000000
さらに、a 番目と b 番目と c 番目のフラグが立っている状態は (1<<a) | (1<<b) | (1<<c) と表せる。
特定のビットのみをLOWにしたい場合
特定のビットのみを1にした値にNOTをかけて反転した値と、現在の値でAND & をとる
#include <iostream> #include <bitset> using namespace std; int main() { int PORTB = 0b00110101; cout << "現在の値:" << bitset<8>(PORTB) << endl; int BIT_FLAG = 1<<5; cout << "操作対象:" << bitset<8>(BIT_FLAG) << endl; PORTB &= ~BIT_FLAG; cout << "計算結果:" << bitset<8>(PORTB) << endl; } // 現在の値:00110101 // 操作対象:00100000 // 計算結果:00010101
特定のビットのみを反転させたい場合
特定のビットのみを1にした値と、現在の値でXOR ^ をとる
#include <iostream> #include <bitset> using namespace std; int main() { int PORTB = 0b00010101; cout << "現在の値A:" << bitset<8>(PORTB) << endl; int BIT_FLAG = 1<<5; cout << "操作対象A:" << bitset<8>(BIT_FLAG) << endl; PORTB ^= BIT_FLAG; cout << "計算結果A:" << bitset<8>(PORTB) << endl; PORTB = 0b00110101; cout << "現在の値B:" << bitset<8>(PORTB) << endl; cout << "操作対象B:" << bitset<8>(BIT_FLAG) << endl; PORTB ^= BIT_FLAG; cout << "計算結果B:" << bitset<8>(PORTB) << endl; } // 現在の値A:00010101 // 操作対象A:00100000 // 計算結果A:00110101 // 現在の値B:00110101 // 操作対象B:00100000 // 計算結果B:00010101
特定のビットがHIGHか確認する場合
特定のビットのみを1にした値と、現在の値でAND & をとり、0以上であればHIGHである
- ビット A の i 番目がHIGHかどうか:if (A & (1<<i))
- ビット A の i 番目がLOWかどうか:if (!(A & (1<<i)))
#include <iostream> #include <bitset> using namespace std; int main() { int PORTB = 0b00110101; cout << "現在の値:" << bitset<8>(PORTB) << endl; int BIT_FLAG = 1<<5; cout << "操作対象:" << bitset<8>(BIT_FLAG) << endl; if (PORTB & BIT_FLAG) { cout << "操作対象はHIGHです。" << endl; } else { cout << "操作対象はLOWです。" << endl; } } // 現在の値:00110101 // 操作対象:00100000 // 操作対象はHIGHです。
まとめ
ビット演算に関して、整理することができた。
| 操作 | ビット演算 |
|---|---|
| ビット A の i 番目をHIGHにする | A |= (1<<i) |
| ビット A の i 番目をLOWにする | A &= ~(1<<i) |
| ビット A の i 番目を反転にする | A ^= (1<<i) |
| ビット A の i 番目がHIGHかどうか | if (A & (1<<i)) |
| ビット A の i 番目がLOWかどうか | if (!(A & (1<<i))) |
パイプライン処理2
現在、CSの勉強のために、コンピュータアーキテクチャ (電子情報通信レクチャーシリーズ)を読んでいる。

前回に引き続き、パイプラン処理についてまとめていく。今回は、データハザードと制御ハザードに対して、どのように対応すべきか確認する。
フォワーディング
パイプライン処理では、直前の命令の結果がレジスタに書き込まれる前に、後続の命令がレジスタの読み出しを行い、命令間にデータの依存性がある場合、更新前の意図していないデータを読み出してしまう。これを書き込む前に読み出してしまうことから、RAW(Read After Write)ハザードと呼ぶ。
RAWハザードを解消するためには、EXステージでの演算結果を、WBステージを経ることなく、次の命令のEXステージの入力としてデータの受け渡しを実現するできればいい。このように本来なら後になるデータの受け渡しを内部資源から先送りするハードウェアを追加することを、フォワーディング(forwarding)またはバイパシング(bypassing)、ショートカット(short cut)と呼ぶ。
以下の命令群を例として、RAWハザードを考える。
sub $s2, $s1, $s3 # デスティネーションレジスタrd($s2)にsubの演算結果を設定 and $t0, $s2, $s4 # 第一オペランドrs($s2)にsubの演算結果を設定 or $t1, $s5, $s2 # 第二オペランドrt($s2)にsubの演算結果を設定 add $t2, $s2, $s2 # ハザードは存在しない sw $t3, 100($s2) # ハザードは存在しない

パイプライン・レジスタのフィールド名による依存関係を明確にすると、RAWハザードが発生する条件は以下の2種類である。
- EX/MEM.RegisterRd == ID/EX.RegisterRs or ID/EX.RegisterRt
- MEM/WB.RegisterRd == ID/EX.RegisterRs or ID/EX.RegisterRt
ただし、命令の中にはレジスタに書き込みを行わないものもあり、不必要にフォワーディングを行ってしまう場合が発生する。そのため、解決策の一つとして、制御信号線のRegWrite信号(レジスタの書き込み信号)が設定されているかを確認する対策がある。
以上のことより、フォワーディング機構を追加した命令パイプラインは以下のようになる。新規に追加した部分がわかりやすいように、データ線は赤色、制御線を緑色とする。

ALUの入力にマルチプレクサ(MUX)を追加して、ID/EXパイプラインレジスタだけでなく、EX/MEMパイプラインレジスタ、MEM/WBパイプラインレジスタから取り出せるようにすることで、任意のデータをフォワーディングすることができる。
フォワーディングの制御回路はEXステージに置かれる。そして、フォワーディングを行うかの判定には、ID/EX.RegisterRsとID/EX.RegisterRtが必要なので、ID/EXレジスタに追加している。
ハザード検出ユニット
データハザードに関して、フォワーディングで解決することができない場合が1つある。それは、ロード命令が書き込むのと同じレジスタを直後の命令が読み出そうとする場合である。

ロード命令がメモリからデータを読み出している最中に、次の命令ではALUでの演算が行われしまっている。そのため、ロード命令とその結果を読み出す次命令との組み合わせに対しては、パイプラインをストールさせなければならない。そこで、「ハザード検出ユニット」を追加する。ハザード検出ユニットはIDステージで動作し、ロード命令とその結果を使用する命令との間にストールを挿入する。

ストールを挿入する条件は以下を同時に満たした場合である。
- ID/EX.MemRead == 1
- ID/EX.RegisterRt == IF/ID.RegisterRs or ID/EX.RegisterRt == IF/ID.RegisterRt
IDステージ上の命令をストールさせる場合、IFステージ上の命令もストールしないと、フェッチした命令が失われてしまう。この2つの命令の進行を止めるために、PCレジスタとIF/IDパイプライン・レジスタび両方を変更しないようにする。これらのレジスタが保持されている限り、IFステージの命令は同じPCから読み出すことができ、IDステージもIF/IDパイプライン・レジスタ中に保持されている同じ命令を使用して読み出すことができる。
EXステージ以降の部分では、何もしない命令(nop)を実行する必要がある。nop命令をパイプラインに挿入する場合、EX, MEM, WBの各ステージの制御信号を全て「0」にする必要がある。制御値が全て「0」の場合、レジスタにもメモリにも書き込みが行われない。
よって、ハザード検出ユニットを追加した命令パイプラインは以下のようになる。新規に追加した部分がわかりやすいように、データ線は赤色、制御線を緑色とする。

ハザード検出ユニットは、PCおよびIF/IDパイプライン・レジスタへの書き込みを制御するとともに、制御値のマルチプレクサ(MUX)を制御する。
命令アドレス生成 MEM→IDに変更
制御ハザードに関して、分岐の判定が完了するまでストールさせていては遅くなりすぎるため、改善策として分岐が不成立すると予測して、後続命令の実行を継続する方法がある。しかしながら、命令が成立した場合、途中まで進めた命令を破棄する必要がある。命令を破棄するには、制御値を全て「0」にすればいい。MEMステージで分岐命令先が確定した後に後続命令を破棄するためには、IF, ID, EXの各ステージ上の命令の制御値を変更する必要がある。先ほどのハザード検出ユニットでは、IDステージの制御値を「0」にして伝播させるだけでよかったが、命令を破棄する場合、パイプラインのIF, ID, EXの各ステージ上の命令を一括消去、すなわちフラッシュ(flush)する必要がある。
分岐の性能を改善する1つの方法は、成立した分岐のコストを下げることである。これまで分岐用の次の次PC値はMEMEステージで取り上げるものと想定してきた。しかしながら、分岐の実行をパイプラインの早いステージに移動することができれば、フラッシュすべき命令数を減らすことができる。
分岐判定を前倒しにするには、分岐先アドレスの計算と分岐判定の評価という2つの処理を早く開始する必要がある。MEMステージからIDステージに変更することで、分岐が成立した場合にもバブルは1つしか発生しないことになる。ただし、IDステージで2つのレジスタを読み出して比較するためにはフォワーディングやハザード検出の回路の追加が必要となる。
次の例の場合、IDステージで比較をする場合、フォワーディングを追加する必要がある。

また次の例の場合、分岐命令の直前のALU命令によって比較のオペランドが算出されるので、EX/MEMのフォワーディングを追加したとしても、ストールが必要である。

さらに、次のようにロード命令の直後に、そのロード結果に基づく条件分岐命令がある場合、2サイクルのストールが必要となる。

よって、命令アドレス生成をMEM→IDに変更し、フォワーディング機構やハザードの検出を追加した命令パイプラインは以下のようになる。

条件が成立した場合に、IFステージ上の命令をフラッシュするための制御線IF.Flashを追加している。この制御線によりIF/IDパイプライン・レジスタの命令フィールドを「0」にクリアする。レジスタをクリアすると、フェッチした命令は何も行わず何も状態を変えないnop命令に変換される。
動的分岐予測
これまで「常に分岐が成立しないと予測」する方式で説明してきた。分岐予測が外れた場合に、パイプラインのステージが増えれば増えるほど、分岐ペナルティは大きくなってしまう。
動的な分岐予測として、2ビット予測器がよく知られている。2ビット予測器の原理は、各分岐命令が2回続けて分岐するか、2回続けて分岐しなかった場合に予測を変える、というものである。

遅延分岐
条件分岐命令で、分岐をしてもしなくても直後に同じ命令を実行すると仮定する。
- 分岐の有無に関わりなく実行する命令(共通命令)を分岐命令の次のアドレス(遅延スロット、deyaled slot)に入れておく。
- 遅延分岐命令は定められた数の共通命令をパイプライン実行した後でPCをセットする。
これによって、もし共通命令が十分な数あれば、分岐によるストールをなくすことができる。
命令スケジューリング
ハザードの解消をソフトウェア的に行うことも重要な技術である。依存関係のある命令をプログラムの中でできるだけ離した位置におくようにすれば、ハザードが起こりにくい。一般に命令の位置を最適化することを命令スケジューリング(instructon scheduling)という。命令スケジューリングはコンパイラが行う。
まとめ
データハザードと制御ハザードを解消するための手法を整理することができた。また、データハザードと制御ハザードの対策を追加して、命令パイプラインを漸く最終形まで持っていくことができた。
関連書籍

パイプライン処理1
現在、CSの勉強のために、コンピュータアーキテクチャ (電子情報通信レクチャーシリーズ)を読んでいる。
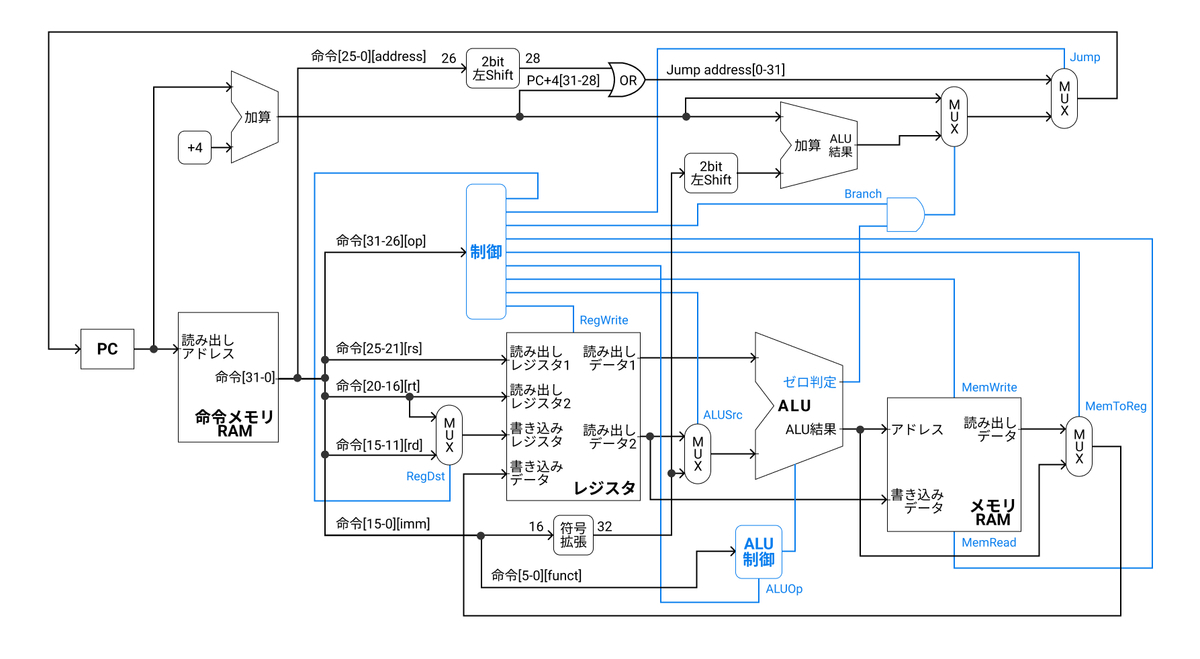
これまで上記のような制御ブロック図で一つの命令がどのように実行されるかを考えてきた。今回は、複数の命令を少しずつずらして同時並行的に実行する、流れ作業のようなパイプライン処理をみていく。
パイプライン処理とは
パイプラインとは、全体の作業を多数の工程に分割し、各工程(ステージ)を並列に処理することで、単位時間あたりの処理量(スループット)を飛躍的に向上させる流れ作業のことである。パイプラインでは全体の作業の実行時間(各工程の作業時間の合計)自体を短くすることはできないが、一連の作業が複数あれば、スループットの向上により一連の作業の全体の時間を短縮することができる。

1~4工程で終わる自動車製造の作業がある、1工程の長さを1時間と仮定する。
一人で全ての工程をこなした場合、1工程ずつしか実施できないので、3台の自動車を製造するまでに要する時間は12時間となる。
次に、4人で協力して各工程を一人が担当し、流れ作業で実施した場合、3台の自動車を製造するまでに要する時間は6時間となる。
流れ作業にすることで、半分の時間で同じ作業を実施することができる。当たり前と言えば、当たり前で日常的に様々な場所で流れ作業(分業)が行われ、効率化が図られている。
命令の実行パイプライン処理
コンピュータの処理もパイプライン化することで処理の効率を飛躍的に高めることができる。コンピュータでは、様々な命令を実行することが作業となる。MIPSの命令は、下記の5ステップを要する。
- 命令フェッチ(Instruction Fetch:IF)
- メモリから命令をフェッチする
- 命令デコードとレジスタフェッチ(Instruction Decode:ID)
- 命令実行・アドレス生成(Execution:EX)
- 命令操作の実行
- 分岐の場合、PC書き換え、アドレスの生成を行う
- メモリアクセス(Memory access:MEM)
- データ・メモリ中のオペランドにアクセスする(メモリへの読み書き)
- 書き込み(Write Back:WB)
- メモリからのデータ(結果)をレジスタに書き込む
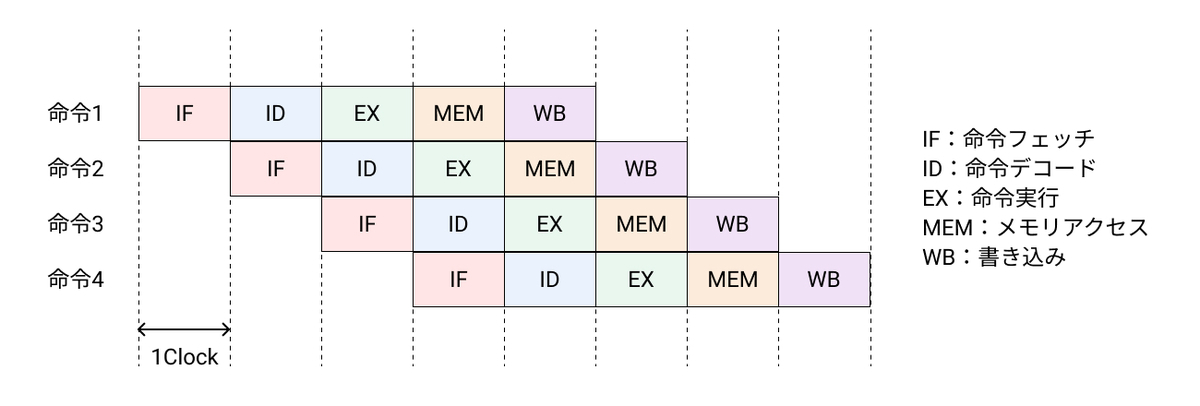
よって、MIPSのパイプラインは5ステージからなる。1クロック・サイクルの間に命令が最大5つ実行されている。
次に、単一クロックサイクルのデータパスを以下に示す。各ステージごとに分割して表示している。

命令の各ステップは左から右の順でデータが流れている。しかしながら、下記の2つだけは例外がある。
- WBステージにおいて、ALU結果・メモリから読み出されたデータがそれぞれ左側へ送られ、レジスタに書き込まれる
- PC更新時に、PC+4または、EXステージで生成された分岐アドレスのいずれかが選択される
右から左に流れるデータは、現在実行されている命令に影響を与えない。しかしながら、パイプラインを後から流れてくる命令に、この例外的なデータの動きが影響を与えてしまう可能性がある。
実際のハードウェアでは、ステージの間がただの結線だと、前のステージの処理の影響が直ちに後のステージの処理に及ぶため、正しいパイプライン動作が行われない。例えば、
- 命令1が、WB(書き込み)ステージ
- 命令2が、MEM(メモリアクセス)ステージ
- 命令3が、EX(命令実行)ステージ
- 命令4が、ID(命令デコード)ステージ
の場合を考える。データ線と制御線が直接接続されていた場合、ID(命令デコード)ステージの命令4のデータが、命令3を実行中のALUの入力線に流れ込むことになり、意図した動作をしなくなってしまう。
これを防ぐために、各ステージの間にレジスタを設け、各ステージ間のデータ・制御の受け渡しを行うようにする。全てのレジスタは、一つのクロックに同期して動作するとする。このようなレジスタをパイプラインレジスタ(pipeline register)と呼ぶ。また、IFステージとIDステージとの間のレジスタは、「IF/ID」と呼ぶ。
パイプラインの阻害要因
パイプライン処理においては、いくつかの阻害要因があり、1クロック1命令のスループットを達成するには様々な工夫が必要である。まずは、阻害要因を以下に列挙する。
オーバーヘッド
本来の処理では存在しなかった、制御上付加された余計な時間のことをオーバーヘッド(overhead)と呼ぶ。
各ステージの処理時間は、処理内容が異なるため、実際にはばらつきがある。そのため、最も時間のかかるステージの処理時間で全体のスループットが決まってしまう。対策としては、出来るだけ各ステージの処理時間の長さを合わせることである。もし長すぎるステージがあれば分割し、短すぎるステージ同士は結合する。
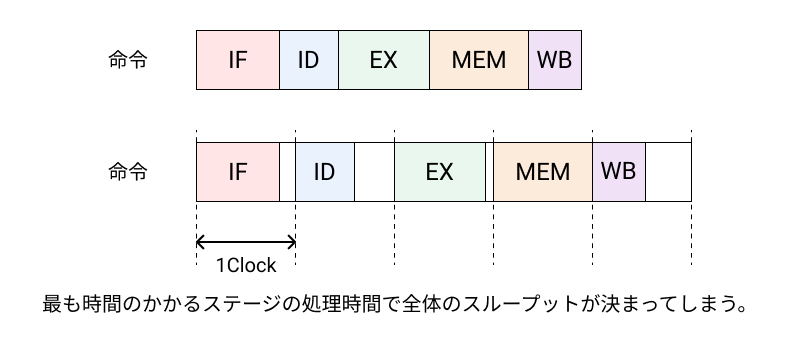
上記にてパイプライン処理を実現するために、パイプラインレジスタを追加した。パイプラインレジスタの読み書きによる遅延も無視することができない。パイプラインのステージ数が増えるほど、相対的にレジスタによるオーバーヘッドが大きくなってしまう。対策としては、出来るだけ高速なレジスタを使うことであるが、限度がある。
ハザード
命令をクロックごとにパイプライン動作させられない状態をパイプラインハザード(pipeline hazard)または単にハザード(hazard)と呼ぶ。そして、ハザードには、構造ハザード、データハザード、制御ハザードの3種類がある。また、ハザードによって命令の実行が止められる状態をストール(stall)と呼ぶ。
構造ハザード
構造ハザード(structual hazard)は、同時に実行される命令の組み合わせにハードウェアが対応できないために、命令を所定のクロックサイクルで実行できない事態が発生することである。
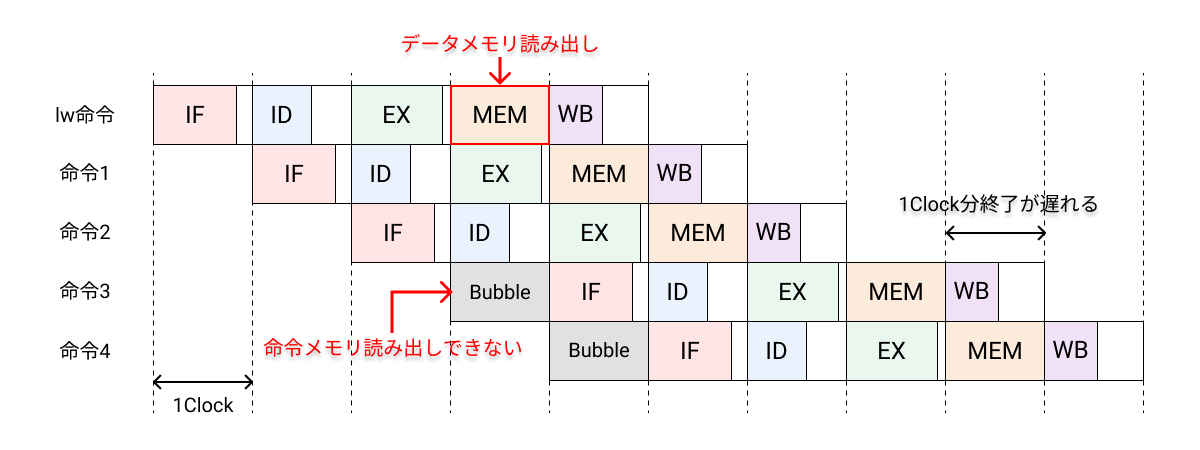
命令メモリとデータメモリを分けることができず、統合メモリを使った場合を考える。同一クロック・サイクルにおいて、最初の命令がメモリのデータにアクセセスしている時に、命令3が同じメモリから命令をフェッチしようとした場合、最初の命令がメモリを占有しているため、命令3は命令をフェッチできない。そのため、命令3を1クロック実行待ちの状態とし、1クロック遅らせる必要がある。
対策としては、資源の多重化によって解決が可能である。上記の場合、命令メモリとデータメモリを別々のものとし、それらのメモリにアクセスするための制御線やデータ線をそれぞれ独立させておく。ただし、コストが高くなってしまうので、コストと性能のトレードオフを考える必要がある。
メモリを分離するのはコストが高く現実的ではないが、キャッシュの分離は可能なので、実際には命令キャッシュとデータキャッシュを独立して設けて、メモリに関する構造ハザードの問題を解決している。
データハザード
データハザード(data hazard)は、命令の実行に必要なデータがまだ利用可能になっていないために、予定している命令を実行できない状況が発生することである。
命令間の依存関係の一つがデータ依存である。データ依存は、命令Aで生成されるデータが命令Bで使われる、というような生産者ー消費者(producer-consumer)の関係のことである。命令Aと命令Bの間に十分な時間があって、両者がパイプライン上に同時に存在しない場合は問題ない。しかしながら、データ依存のある2命令が接近している場合にストールが発生してしまう。
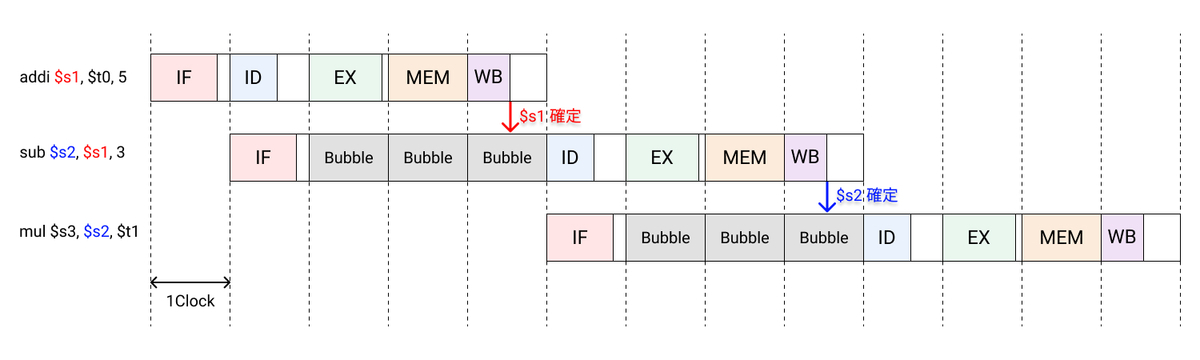
WBステージでレジスタに書き込みが行われるため、バブルを追加しない場合、$s1や$s2の演算結果を取得できず、演算前に格納されていたデータを読み出してしまうことになる。3つの命令の実行は本来7クロックで終了するが、上記では13クロックと約2倍になっており、スループットは約半分になってしまう。
5ステージでの命令パイプラインの場合、4命令以上離れた命令の間ではデータハザードは起こらない。
制御ハザード(分岐ハザード)
制御ハザード(control hazard)は、分岐ハザードとも呼ばれ、分岐命令が原因で次に実行する命令の確定ができないことから発生する。条件分岐で実行の流れが二つに分かれる場合、条件の評価を待たずに先行して片方の分岐の命令群をパイプラインに投入することになる。そして条件を評価した結果もう一方に分岐することが確定した場合、パイプラインの内容を破棄して正しい分岐の命令群を投入しなおさなければならない。
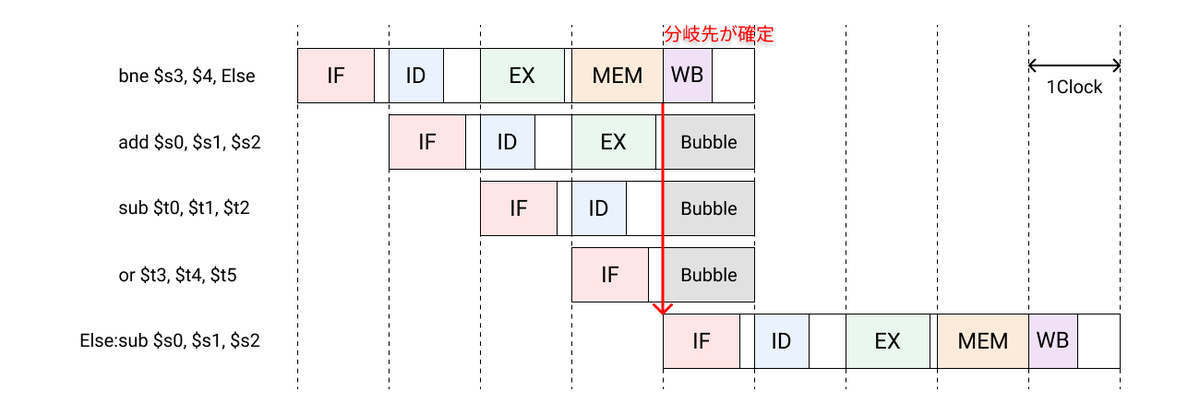
分岐するかの判定は、MEMステージに至るまで決定されない。分岐が完了するまでストールさせては速度が遅くなりすぎるので分岐が不成立と予測して、後続の命令の実行を継続させる。分岐が成立した場合に、フェッチおよびデコードを進めていた命令を破棄し、分岐先の命令から処理を続行する。
もし分岐先が決定するまでストールさせる場合、3クロック分ストールさせることになる。
まとめ
今回は、パイプライン処理の概要とその阻害要因を確認することができた。次回、阻害要因の詳細とどのように対策すべきか確認していく。