【Rails】camelCase⇆snake_caseの変換
今回は久しぶりのRailsアプリケーション開発。
社内の一部業務の自動化のために簡単なアプリケーションを前任者から引継ぎ、一部改良を行った。構成はバックエンドがRuby on Railsで、フロントエンドがNuxt.jsの構成だ。
インターフェースとしてAPIを実装する中で、「jsonデータのkeyに関して、Rails側ではsnake_case、フロント側ではcamelCaseで扱いたい」と思った。フロント側で$axiosのmiddlewareでsnake_case⇆camelCaseの変換を行うことも考えたが、今回Rails側で対応を行った。その方法を備忘録として残しておく。
- Ruby:v3.0.1
- Ruby on Rails : v6.1.3.2
- active_model_serializers:v0.10.12
命名規則に関して
Rubyの命名規則
復習も兼ねて、Rubyスタイルガイドから命名規則について列挙しておく。
- シンボル、メソッド、変数には
snake_caseを用いる- 文字と数字を分離しない(×:var_10, ○:var10)
- 述語(boolean値が返る)メソッドは疑問符で終わる(ex.empty?)
- 危険な可能性(破壊的な変更)のあるメソッドは感嘆符で終わる(ex.update!)
- クラスやモジュールには
CamelCaseを用いる - 定数は
SCREAMING_SNAKE_CASEを用いる
JavaScriptの命名規則
復習も兼ねて、Google JavaScript Style Guideから命名規則について列挙しておく。
- メソッド、変数には(先頭小文字の)
camelCaseを用いる - クラスには(先頭大文字の)
CamelCaseを用いる - 定数は
SCREAMING_SNAKE_CASEを用いる
RequestのkeysをcamelCaseからsnake_caseへ変換
Requestに関しては、before_actionでparamsを変換するように、以下の処理を追加した。
class ApplicationController < ActionController::API before_action :snake2camel_params def snake2camel_params params.deep_transform_keys!(&:underscore) end end
deep_transform_keys!は、ハッシュに対して、ブロック内で変換されたキーを含むハッシュに変換してくれる破壊的メソッドである。ソースコードは以下のようになっている。
class Hash # 〜省略〜 # Destructively converts all keys by using the block operation. # This includes the keys from the root hash and from all # nested hashes and arrays. def deep_transform_keys!(&block) _deep_transform_keys_in_object!(self, &block) end # 〜省略〜 private # Support methods for deep transforming nested hashes and arrays. def _deep_transform_keys_in_object!(object, &block) case object when Hash object.keys.each do |key| value = object.delete(key) object[yield(key)] = _deep_transform_keys_in_object!(value, &block) end object when Array object.map! { |e| _deep_transform_keys_in_object!(e, &block) } else object end end end
underscoreでkeyをcamelCaseからsnake_caseへ変換している。ソースコードは以下のようになっている。
class String # 〜省略〜 def underscore ActiveSupport::Inflector.underscore(self) end end
module ActiveSupport module Inflector # 〜省略〜 def underscore(camel_cased_word) return camel_cased_word unless /[A-Z-]|::/.match?(camel_cased_word) word = camel_cased_word.to_s.gsub("::", "/") word.gsub!(inflections.acronyms_underscore_regex) { "#{$1 && '_' }#{$2.downcase}" } word.gsub!(/([A-Z\d]+)([A-Z][a-z])/, '\1_\2') word.gsub!(/([a-z\d])([A-Z])/, '\1_\2') word.tr!("-", "_") word.downcase! word end end end
実装方法に関して
&:underscoreはブロック変数ではなく、& + Symbolオブジェクトを用いている。(Use fast ruby idioms by oniofchaos · Pull Request #32337 では、ブロック変数を用いるブロック渡しより、&:メソッド名渡しの方が高速だと説明されている。)
&はProc coercion演算子とも呼ばれ、SymbolオブジェクトをProcオブジェクトに変換する。そのために、Symbol#to_procが呼び出される。- Symbol#to_procでは、ブロック引数に対してSymbolオブジェクトのメソッドが呼び出される。
params.deep_transform_keys!(&:underscore) # 同じ実装である params.deep_transform_keys!{|key| key.underscore}
(復習)RubyのSymbolとは何か?
Rubyの内部実装では、メソッド名や変数名、定数名、クラス名などの`名前'を整数で管理しています。これは名前を直接文字列として処理するよりも速度面で有利だからです。そしてその整数をRubyのコード上で表現したものがシンボルです。
Responseのkeysをsnake_caseからcamelCaseへ変換
jsonデータへの整形も含め、Active Model Serializersを用いた。その場合、initializersに以下のファイルを追加するだけでsnake_caseからcamelCaseへ変換することができた。
ActiveModelSerializers.config.key_transform = :camel_lower
公式ドキュメントは以下を参考にして欲しい。
ActiveModelSerializersの使い方
- gem追加
gem 'active_model_serializers'
- モデル生成
rails g serializer <-ModelName-> ex. rails g serializer User
class UserSerializer < ActiveModel::Serializer attributes :id, :name, :email attribute: :password, if: -> {instance_options[:password]} has_many :posts has_many :tasks end
- controllerにシリアライザーを指定
class UsersController < ApplicationController def index users = User.all.includes(:posts) render json: users, each_serializer: UserSerializer, #複数の場合、each_serializer include: ['posts'] #アソシエーションを指定 end def show users = User.find(params[:id]) render json: users, serializer: UserSerializer, #単数の場合、serializer password: true #オプション指定 end end
アソシエーションを指定する場合、N+1問題が発生する場合があるので、includesメソッドを使うなど対応が必要となる。
また、アソシエーションを指定することでActiveModelSerializers側でクエリを発行することもできるのでパフォーマンスなどはよく確認する必要があるように思えた。
まとめ
ActiveModelSerializersは、RailsでAPIを実装する際にとても便利なGemであるように思えた。この便利なGemのお陰で、爆速でAPIが開発できるように感じた。
もっと他にいい方法があれば、是非教えてください。よろしくお願いします。
入出力と周辺装置
現在、CSの勉強のために、コンピュータアーキテクチャ (電子情報通信レクチャーシリーズ)を読んでいる。
ようやく最後の章になった。
CPUは様々な周辺装置と情報やりとりをしながら処理を進めている。CPUと周辺装置の情報交換のやり方についてまとめていく。
周辺装置の分類
CPUから見た入出力の周辺装置としては以下のようなものが挙げられる。
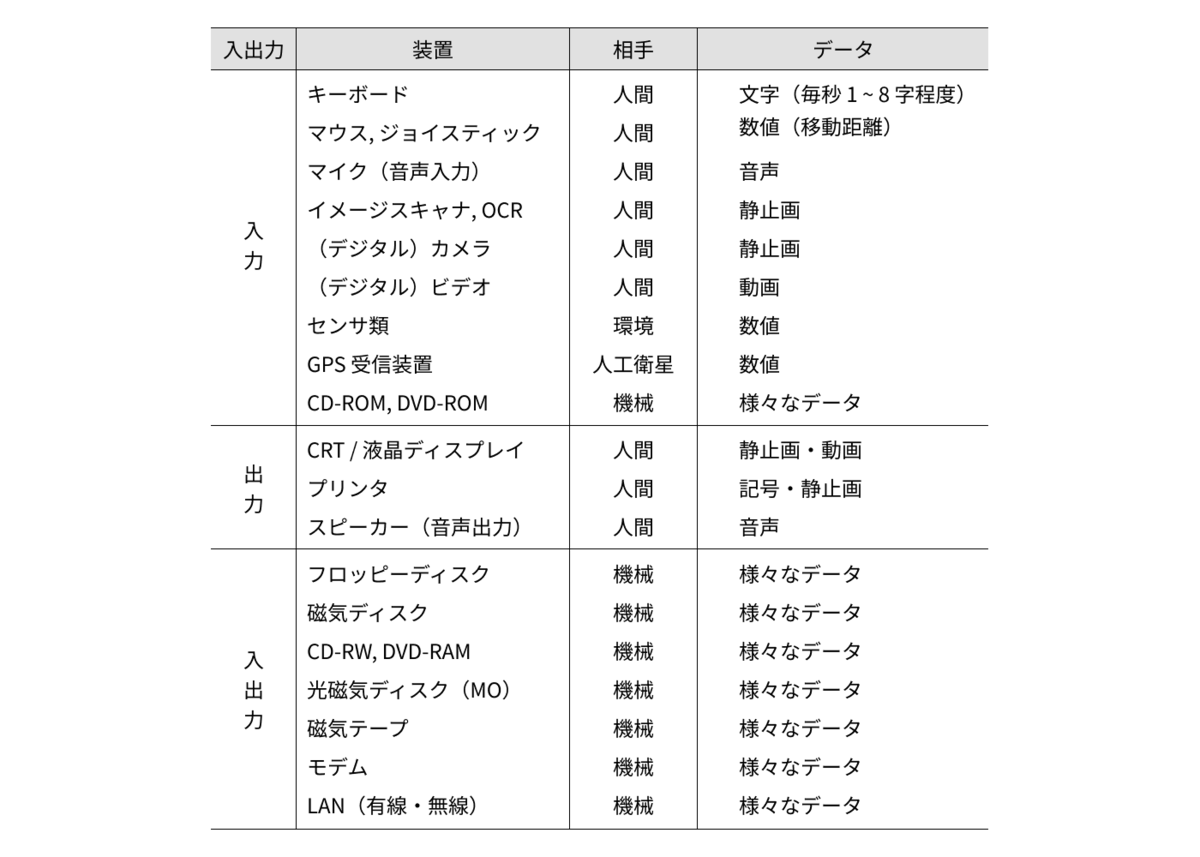
周辺装置をデータの送受信装置として見た場合、高いスループット、素早い応答、実時間性、高い頻度の入出力など、それぞれに要求されるものが異なる。この多様性を満足するためのインターフェースがコンピュータには必要となる。
各デバイスの原理や詳細に関しては今回省略するが、技術の発展に伴い、ハードウェアも大きく変わってきている。
ハードウェアインターフェース
CPUと周辺機器の接続は、通常バスを用いて行われる。

CPUや主記憶装置、入出力装置などのそれぞれの装置が共通の伝送路であるバスで接続されている。バスには以下の2種類がある。
- 内部バス(CPU内部バス)
- CPU内部のデータのやり取りに使用する伝送路
- CPU内部の制御装置や演算装置・キャッシュメモリなどのデータ・信号をやり取りするバス
- 外部バス
また、上記のバスで伝送する信号に応じて3つの伝送路がある。
- アドレスバス
- メモリのアドレスや入出力装置(I/O)のアドレスを出力するために使われるバス
- 線の本数を「アドレスバス幅」という
- データバス
- CPUと、メモリや入出力装置(I/O)との間でデータを転送するために使われるバス
- コントロールバス(制御バス)
- 各バスを制御するバス制御用のバス
- アドレスバスやデータバスで実際に入出力を行うタイミングや、その他CPUと外部との間での必要な制御情報をやり取りするために使われるバス
データ転送の手順
周辺装置との入出力は、以下の手順で行われる。
- ポーリングまたは割り込みによる入出力の起動
- 前処理
- 命令またはDMA(Direct Memory Access)による主記憶・周辺装置間のデータ転送
- 後処理
ポーリングと割り込みの違い
- ポーリング(polling)
- CPUが定期的に順番に周辺装置を見回って、入出力の要求があるかどうかを確認する方式
- メリット
- 実装が簡単
- CPU側の前処理・後処理が軽くて済む
- デメリット
- 入出力が即時的に行えない
- 見回りのために無駄な時間が多く使われる
- 割り込み(interrupt)
- 周辺装置(のコントローラ)からCPUに対して割り込み信号を入れ、例外処理を要求して、入出力を行わせる方式
- メリット
- 待ち時間や見回り時間の問題を解決することができる
- デメリット
- CPUのハードウェアが複雑
- 実行中の命令を中断することになるので、レジスタ退避やキャッシュの書き戻しなどが必要となり、前処理・後処理のオーバーヘッドがかかる
主記憶と周辺装置の間でのデータ転送方式
- CPUを介してデータ転送を行う方式
- DMA(Direct Memory Access)

割り込みの調停
1つのバスに複数の入出力機器がつながっているため、割り込みの衝突が発生する可能性がある。複数の入出力機器からの割り込みに対して、1つを選択する必要がある。この調整を行うのが「アービタ(arbiter, 調停器)」である。

- 同じ優先度の割り込み要求は優先度ごとに決められたランダムアービタに繋ぎ込まれ、その中からランダムに1つを選ぶ。乱数的に選ぶことで、各要求に対する公平さを保証している。
- プライオリティエンコーダは、これらの中から優先度の最も高い割り込みを選び、それをエンコードしてCPUに送る。
- CPUが割り込みを許可すれば、周辺機器とCPU間でデータ転送が行われる。
例外処理
入出力に伴う割り込みは、例外処理(exception handling)を引き起こす。コンピュータでは様々な例外が発生するが、その性質に応じて優先度や処理内容が定められている。
例外とは、通常のプログラムにはない処理が必要な状態のことである。

優先度に関しては、一般的にハードウェアエラーが優先度が最も高く、次に命令実行による例外、最後にプログラム外割り込み、という順番になる。
例外処理の手順は以下の通りである。
- 例外処理の要因が発生したら、CPUはこれを受け付けるかどうか決める。複数の要因が重なった場合には、最も高い優先度の要因を1つ選択する。
- 受け付けることが決まった場合、現在実行中のプログラムの状態を退避する。具体的にはデータレジスタ、PC、状態レジスタなどをメモリ上の適切な場所に退避する。
- 例外処理のカーネルプログラムを起動する。カーネルプログラムは例外の要因を知って、必要な処理を行う。
- 例外処理が終わったら、必要に応じてPCなどの値を復帰し、元のプログラムの実行に戻る。
まとめ
これまでは主にCPU内部を見てきたが、今回CPUと周辺装置との繋がり、およびデータ転送方法について確認することができた。
例外や割り込みに関しては、もっと奥が深いのでもっと理解度を深めていきたい。
関連書籍
")
アウトオブオーダ処理
現在、CSの勉強のために、コンピュータアーキテクチャ (電子情報通信レクチャーシリーズ)を読んでいる。
アウトオブオーダ処理とは
プログラムにおいて、実行結果が変わらないように配慮し、データなどの依存関係から見て処理可能な命令について、命令実行・完了の順番を変更することで、並列度をあげ、性能を向上させる手法。
- アウトオブオーダ処理(out of order):命令を動的に入れ替えて、依存関係がない順で順次実行する方式。
- インオーダ処理(in order):命令を読み込んだ順番通りに実行する方式。
順番を入れ替えるタイミングで2種類ある。
- アウトオブオーダー実行(out of order execution)
- 命令をEXステージに入れる順番を入れ替える
- アウトオブオーダー完了(out of order completion)
- 実行結果をレジスタに格納する順番を入れ替える
例)以下の実行環境下での次のプログラムの実行時間を計算する。
- ALU(加減算・論理演算):2つ / 演算時間:1
- 乗算ユニット:2つ / 演算時間:3
- 命令フェッチは同時に2命令
- レジスタは同時に4出力2入力

インオーダ実行 / インオーダ完了

実行時間:12クロック
インオーダ実行 / アウトオブオーダ完了

実行時間:11クロック
アウトオブオーダ実行 / インオーダ完了

実行時間:10クロック (但し、HWの追加変更を行なっている)
アウトオブオーダ実行 / アウトオブオーダ完了

実行時間:9クロック (但し、HWの追加変更を行なっている)
データ依存再考
データ依存性の分類
- フロー依存(flow dependence)
- 命令Aで書き込んだ値を後続の命令Bで読み出すことで起こる A => B の依存関係
- プログラム固有の依存であり、真の依存関係
- (解決策1)フォワーディング
- ハードウェアでAの結果出力からBの演算入力までのデータ遅延(latency)を出来るだけ短くする
- (解決策2)値予測
- Aの結果を予測する技術
- 逆依存(anti dependence)
- 命令Aで読み出したレジスタ(メモリ語)に後続の命令Bが書き込みを行うことで起こる A => B の依存関係
- 主にレジスタの不足からくる依存
- (解決策)レジストリネーミング
- 出力依存(output dependence)
- 命令Aで書き込んだレジスタ(メモリ語)に後続の命令Bが再度書き込みを行うことで起こる A => B の依存関係
- 主にレジスタの不足からくる依存
- (解決策)レジストリネーミング
(2)と(3)は、主にレジスタ数の不足からくる依存である。特にインオーダ処理用のコンパイラ最適化がなされた機械語プログラムでは、レジスタ数が最小化されている場合が多く、インオーダ処理をしている限りは問題にならない。しかしながら、アウトオブオーダ処理ではこれが障害になる。
データ依存とデータハザードの関係性
| データ依存 | データハザード |
|---|---|
| フロー依存 | RAW(read after write)ハザード |
| 逆依存 | WAR(write after read)ハザード |
| 出力依存 | WAW(write after write)ハザード |
上記の3つの依存関係が現れるプログラムを示す。

また、以下の条件下で動作させる場合のパイプラインを考えてみる。
- ALU(加減算・論理演算):2つ / 演算時間:1
- 乗算ユニット:2つ / 演算時間:3(3段階のステージで分割)
- 命令フェッチは同時に2命令
- レジスタは同時に4出力2入力

アウトオブオーダ実行が可能であっても、データ依存性からくるハザードによって、実行時の並列度が下がることがある。
アウトオブオーダ処理の機構
アウトオブオーダ処理のためには、多数の命令の中で現在実行可能な命令がどれかを選択する必要がある。そのためには、現在実行中の命令とまだ実行していない命令の間の依存関係を検出して、依存関係による待ちがない命令を選んで実行する必要がある。
実行可能な命令を選び出すための機構を「命令ウィンドウ(Instruction Window)」という。命令ウィンドウはデコードが終わった複数の命令を入れておくバッファであり、その中で依存関係と資源競合による待ちがなくなった命令を取り出す機構を備えている。
逆依存と出力依存はレジストリネーミングによって解決されるので、命令ウィンドウではフロー依存のみを解決すればよい。フロー依存を検出するために、各命令の入力データの入出力が揃ったか否かを明示するフラグを命令ウィンドウに持たせる。

命令ウィンドウの種類
- 集中形
- 命令ウィンドウをプロセッサ全体に1個置く
- メリット
- 無駄にメモリを確保する必要がない
- デメリット
- 回路が複雑になる
- 遅延が大きくなる可能性がある
- 分散形
- 各演算ユニットの前段に命令ウィンドウを分散配置する
- 分散配置した命令ウィンドウをリザベーションステーション(reservation station)と呼ぶ
- メリット
- 各リザベーションステーションの規模が小さくて済むため、高速動作が可能
- デメリット
- 分散配置するため、全体として回路規模が大きくなってしまう
レジストリネーミング
逆依存と出力依存は、レジスタ番号の衝突によるものであり、レジスタ数さえ十分にあれば、依存関係を継承することができる。レジスタ番号の置き換えによって並列性を向上させることを、レジストリネーミング(register renaming)と呼ぶ。
ソフトウェアによるレジストリネーミング
 以前は実行時間が12クロックだったが、ソフトウェアによるレジスタ番号の置き換えを行うことで、実行時間が9クロックになった。レジストリネーミングにより3クロック短縮することができた。
以前は実行時間が12クロックだったが、ソフトウェアによるレジスタ番号の置き換えを行うことで、実行時間が9クロックになった。レジストリネーミングにより3クロック短縮することができた。
マッピングテーブル
 命令がフェッチされると、当該命令が書き込むレジスタの論理アドレスに対するマッピングテーブルのエントリに、1個の物理レジスタアドレスが書き込まれる。以後、この物理レジスタアドレスを使って計算が進められる。
命令がフェッチされると、当該命令が書き込むレジスタの論理アドレスに対するマッピングテーブルのエントリに、1個の物理レジスタアドレスが書き込まれる。以後、この物理レジスタアドレスを使って計算が進められる。
実行時間は10クロックになった。ソフトウェアによるレジストリネーミングに追加で、リネームのステージが追加されている。
リオーダバッファ

図のようにレジスタと並べて、命令の実行結果を格納するメモリ、リオーダバッファを設ける。リオーダバッファのエントリには、命令が書き込むレジスタのアドレスと、その値の組が格納される。命令がフェッチされると、リオーダバッファに新しいエントリが確保され、当該命令が書き込むレジスタアドレスとwaitタグが書き込まれる。また、命令はリオーダバッファから、このレジスタが読み出すレジスタのアドレスが含まれるエントリのうちで最新の値を読み出す。
命令はリオーダバッファを用いて整形され、レジスタ番号はリオーダバッファのエントリ番号に置き換えられ、命令ウィンドウに送られる。命令ウィンドウは、オペランドデータが全て揃った命令の中で適当なものを実行ユニットに送る。オペランドがwaitタグの場合、データが揃わないので実行ユニットに送られない。命令実行結果をフォワーディングすることにより、データが揃った時点で実行ユニットに送られる。
エントリ番号は命令ごとに異なるため、逆依存や出力依存は発生せず、WARハザード、WAWハザードは起こらない。
また、リオーダバッファのエントリは以下の2つの条件を満たした時に、値をリオーダバッファからレジスタに移す。
- このエントリに書き込んだ命令以前の命令が終了した
- このエントリのレジスタ値が確定し、書き込まれた
まとめ
命令を動的に入れ替えて、依存関係がない順で順次実行する、アウトオブオーダ処理について理解を深めることができた。
効率のいいアウトオブオーダ処理は、命令ウィンドウとレジスタリネーミングによって実現されていることがわかった。

関連書籍
並列処理(2)静的最適化
現在、CSの勉強のために、コンピュータアーキテクチャ (電子情報通信レクチャーシリーズ)を読んでいる。
コンピューターの性能向上には、並列処理が必要不可欠である。前回に引き続き、静的最適化に関してまとめていく。静的最適化(static optimization)とは、プロセッサを効率良く動かすために、あらかじめ機械語プログラムを最適化することを指す。一般的にはコンパイラで行われる。
機械語プログラムと命令間依存性
ハザードを出来るだけ減らすためにコンパイラができることとして、以下が挙げられる。
- 依存関係を解消したり減らしたりする
- ループアンローリング
- 複数のループを統合して1つのループにすることで、分岐命令によるハザードをなくす手法
- トレーススケジューリング
- 分岐予測をして複数の基本ブロックを統合し、制御依存を減らす手法
- ループアンローリング
- 依存関係のある命令どうしをプログラムの中で離れた位置に置く
- ソフトウェアパイプライニング
- ループ間にまたがって命令を移動し、依存関係のある命令どうしの距離を離すことでハザードを起こりにくくする手法
- ソフトウェアパイプライニング
但し、上記はプログラムの意味を変えない範囲で行わなければならない。
例として、配列aのすべての要素に5を加えるプログラムを考える。
for (i=0; i < 100; i++) { a[i] = a[i] + 5; }

- 実行環境は以下を想定する。
- ALU:2つ
- 命令フェッチ・結果書き戻し:同時に2命令実行可能
- レジスタ:同時に4出力2入力
上記のプログラムにおいて、blt r1, r2, ForLoopの分岐命令で制御ハザードが発生する。分岐命令があるたびに、3クロックのストールが生じてしまう。また、並列処理を行う場合には、分岐命令をまたぐ並列化は通常行われない。

但し、今回のループにおいて、if (r1 < r2)はr1を1ずつインクリメントしているだけのため、r1=100になる最後以外は分岐予測(常に分岐しないと予測)が100%当たるため、制御ハザード解消のために分岐予測を行う。

ループ1周は、9クロックで実行される。
ループアンローリング
ループアンローリングは、複数のループを統合して1つのループにすることで、分岐命令によるハザードをなくす手法である。今回の場合、100回のループを4つのループにまとめて1つにする。アセンブリ言語は以下の通りである。

パイプラインは以下の通りである。

ループ4周分で13クロックで実行される。
先ほどの分岐予測の場合と比較して、9クロック×4周=36クロックとなるため、36 / 13 = 2.77倍の性能が出ている。
ループアンローリングによる効率改善の理由
- 分岐命令の削減(
bltが3つ減ったこと)- 分岐命令は並列化しないので、
bltを3つ削減することで、3クロック削減できる
- 分岐命令は並列化しないので、
- lw, addi, swをそれぞれ4つずつまとめることによるデータハザードの解消
- 依存関係がある命令を離すことでデータハザードが起こらなくすることができる
ソフトウェアパイプライニング
ソフトウェアパイプライニングは、ループ間にまたがって命令を移動し、依存関係のある命令どうしの距離を離すことでハザードを起こりにくくする手法である。また、ソフトウェアパイプライニングとループアンローリングは組み合わせて用いることができる。
今回においては、ループの最初で依存関係のある命令が連続している。

この部分をループをまたがって処理できるように移動させる。すなわち、ループの中ではa[i]に計算済みの値を代入し、次のループi+1番目の計算を行うようにする。以下のようなプログラムになる。
- r5 = a[0] + 5
- r4 = a[1]
- i = 0の時
- a[0] = r5 (= a[0] + 5)
- r5 = r4 + 5 (= a[1] + 5)
- r4 = a[2]
- i = 1の時
- a[1] = r5 (= a[1] + 5)
- r5 = r4 + 5 (= a[2] + 5)
- r4 = a[3]
- i = 2の時
- a[2] = r5 (= a[2] + 5)
- r5 = r4 + 5 (= a[3] + 5)
- r4 = a[4]
アセンブリ言語は以下の通りである。

パイプラインは以下の通りである。

ループ1周は、8クロックで実行される。
先ほどの分岐予測の場合と比較して、9 / 8 = 1.13倍の性能が出ている。
ソフトウェアパイプライニングによる効率改善の理由
- lw, swの命令どうしの距離を離すことによるデータハザードの解消
トレーススケジューリング
トレーススケジューリングは、分岐予測をして複数の基本ブロックを統合し、制御依存を減らす手法である。
- 基本ブロック:ある分岐命令の直後から次の分岐命令までの命令列
- 制御フローグラフ:プログラムを基本ブロックの間の依存関係として表現したもの

トレーススケジューリングの手順
- 実行履歴(プロファイル / profile)などによって、実行される確率の最も高い分岐パターンを調べる。
- (1)のパターンの上にある基本ブロックを統合する。これをトレース(trace)と呼ぶ。
- トレースに命令スケジューリングを施すことで、トレース内の実行効率を高める。トレース内にも分岐命令はあるが、「分岐命令を超えた命令移動」も行う。
- (3)によってトレース以外に分岐する場合に生じる不都合を防ぐため、分岐先の入り口に補正用のコードを入れる。これをブックキーピング(bookkeeping)と呼ぶ。
- トレースを除いた制御フローグラフにおいて、(1)~(4)を繰り返す。
今回の配列のループにおいては、条件分岐が複数あるわけではないので、トレーススケジューリングを用いることはできない。
まとめ
コンパイルによる静的最適化に関して、具体的な例を通してどのような手法があるのか、またそのやり方含め、理解を深めることができた。
関連書籍
並列処理(1)
現在、CSの勉強のために、コンピュータアーキテクチャ (電子情報通信レクチャーシリーズ)を読んでいる。
コンピューターの性能向上には、並列処理が必要不可欠である。今回は並列処理に関してまとめていく。
命令レベル並列処理
以前の記事で、パイプラインの話をした。パイプラインは、全体の作業を多数の工程に分割し、各工程(ステージ)を並列に処理することで、単位時間あたりの処理量(スループット)を飛躍的に向上させる技術であった。
パイプラインの阻害要因のうち、パイプラインレジスタの動作遅延だけはボトルネックになってしまい、スループットはレジスタの遅延で縛られている。
上記の問題を解決する手段の一つとして、並列処理が挙げられる。並列処理には以下の2パターンがある。
- 複数のプロセッサによる並列化(マルチプロセッサ)
- 1つのプロセッサ内の複数の演算器による並列化
今回は、後者の複数の演算器による並列化を考える。
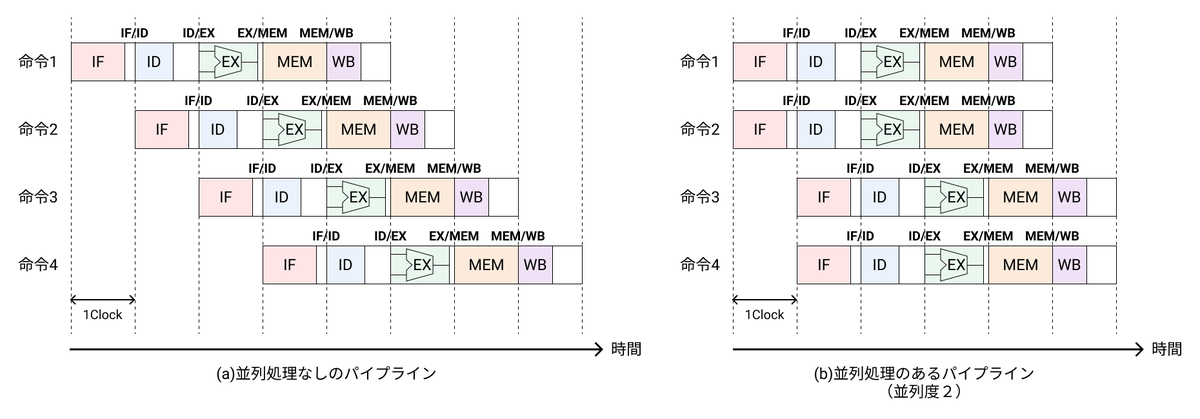
並列化することで、単位時間あたりに実行できる命令の数が増えるので、並列処理がない場合と比較して、2倍のスループットになる。理想的には、並列度Pの場合、P倍のスループットが得られる。
並列処理パイプライン
並列処理の前に、簡易的な通常のパイプラインのブロック図を示す。

各パイプラインレジスタでデータの受け渡しを行い、ステージごとに区切られている。上記のパイプラインを並列化するために、ALUを二つ設置すると以下のようなパイプラインのブロック図となる。

命令レベル並列処理に必要な事項
命令レベル並列処理の方式は、「4. 並列実行の制御」の解決法によって分類される。
VLIW(Very Large Instruction Word)
- 1命令の中に複数の演算を入れたアーキテクチャである
- 命令語長が100ビット以上の長大なものになることから「Very Large Instruction Word」略称VLIWと言われている
同一命令語中のハザードはすべてコンパイラ(または機械語プログラマ)が静的に解決し、命令語の中の演算はすべて同時に実行する
利点
- プロセッサの制御ロジックが簡単(高速)
- 並列化にあたりハザード検出にハードウェアが介在しない
- 問題点
- 透過性・互換性がない
- 機械語プログラムがハードウェアに対して固定されてしまい、互換性がない
- プロセッサの中の演算器の構成によって命令の形式が決まり、構造ハザードから1命令中に可能な演算の組み合わせが決まる
- 静的な並列化の限界
- (解決策)トレーススケジューリング(などの大域的フィールドの最適化)を行う
- 十分に並列化できない場合の命令フィールドの無駄
- (解決策)命令メモリ中では各命令を圧縮して置いておき、キャッシュにコピーするときやデコードするときに本来の姿に戻す
- 透過性・互換性がない
VLIWは、透過性や互換性を犠牲にしてハードウェアを簡単化し、クロックサイクルを短くすることで高速な並列処理を実現する方式である。
スーパスカラ
- 逐次型プログラムを並列実行するアーキテクチャである
- ハードウェアがハザードを検出し、並列可能な命令を選んで並列実行する
- 利点
- 透過性・互換性が維持される
- 問題点
- ハードウェアの複雑化
スーパスカラプロセッサで、2命令同時処理可能なパイプラインの構成図を示す。

大きな変更点としては、命令をデコードする前に、ハザード検出を行う「プリデコーダ」を追加している。
パイプラインの流れは以下となる。
- 命令フェッチ(Instruction Fetch:IF)
- メモリから複数の命令をフェッチする
- 命令プリデコード(Instruction preDecode:ID1)
- フェッチした命令と処理待ちの命令の全ての依存関係を調べ、もし依存関係があれば処理を遅らせる
- 依存関係のない命令を「実行命令レジスタ」に入れる
- 命令ポストデコードとレジスタフェッチ(Instruction Dispatch:ID2)
- 命令実行・アドレス生成(Execution:EX)
- 命令操作の実行
- 分岐の場合、PC書き換え、アドレスの生成を行う
- メモリアクセス(Memory access:MEM)
- データ・メモリ中のオペランドにアクセスする(メモリへの読み書き)
- 書き込み(Write Back:WB)
- メモリからのデータ(結果)をレジスタに書き込む
並列処理とハザード
プリデコードにおけるハザード検出について確認する。
- 構造ハザード
- 並列処理では、ユニット数やポート数が足りないために、構造ハザードが発生する
- 上図では、各ALUごとにデータキャッシュを設けたが、もし2つのALUに対して1つのデータキャッシュしかない場合、データキャッシュは1回に1つしかアクセス要求を受け付けることができない。すなわち、ロード/ストア命令を同時に2つ以上実行することができない。これが典型的な構造ハザードである。
- (解決策)競合する資源を使う命令を、時間をずらして順番に処理する
- データハザード
- 並列する2つの命令の間にはデータ依存関係があってはならない
- プリデコードのステージでデータ依存関係を発見したら、プログラムの中で前に出てくる命令を先に処理し、後の命令は時間をずらして後から処理することになる
- 制御ハザード
- フェッチした命令のどちらかが分岐命令の場合、制御ハザードが起こる可能性がある
- 並列処理をする場合、ストール(ハザードにより命令の実行が止められる状態)の影響は大きくなる
- 遅延分岐はたくさんの共通命令(分岐の有無に関わらず実行する命令)を必要とする
- 分岐予測が外れた場合のペナルティが大きい
まとめ
複数の演算器による並列化に関して、LVIW(Very Large Instruction Word)方式とスーパスカラ方式について理解を深めることができた。
| LVIW | スーパスカラ | |
|---|---|---|
| 透過性・互換性 | × | ○ |
| ハザード検出・並列化 | 静的(コンパイラ) | 動的(H/W) |
| ハードウェア | 簡単 | 複雑 |
| 制御の遅延 | 小 | 大 |
| 命令フィールドの無駄 | 有 | 無 |