並列処理(1)
現在、CSの勉強のために、コンピュータアーキテクチャ (電子情報通信レクチャーシリーズ)を読んでいる。
コンピューターの性能向上には、並列処理が必要不可欠である。今回は並列処理に関してまとめていく。
命令レベル並列処理
以前の記事で、パイプラインの話をした。パイプラインは、全体の作業を多数の工程に分割し、各工程(ステージ)を並列に処理することで、単位時間あたりの処理量(スループット)を飛躍的に向上させる技術であった。
パイプラインの阻害要因のうち、パイプラインレジスタの動作遅延だけはボトルネックになってしまい、スループットはレジスタの遅延で縛られている。
上記の問題を解決する手段の一つとして、並列処理が挙げられる。並列処理には以下の2パターンがある。
- 複数のプロセッサによる並列化(マルチプロセッサ)
- 1つのプロセッサ内の複数の演算器による並列化
今回は、後者の複数の演算器による並列化を考える。
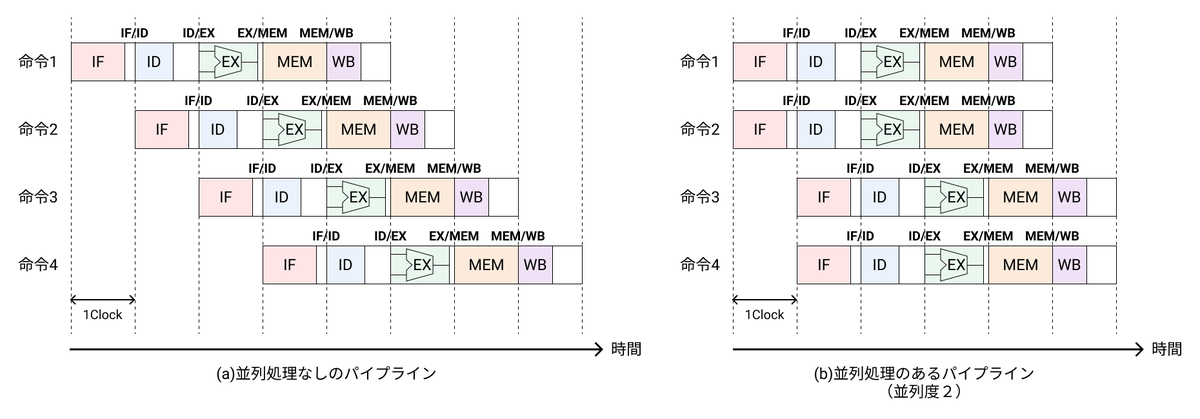
並列化することで、単位時間あたりに実行できる命令の数が増えるので、並列処理がない場合と比較して、2倍のスループットになる。理想的には、並列度Pの場合、P倍のスループットが得られる。
並列処理パイプライン
並列処理の前に、簡易的な通常のパイプラインのブロック図を示す。

各パイプラインレジスタでデータの受け渡しを行い、ステージごとに区切られている。上記のパイプラインを並列化するために、ALUを二つ設置すると以下のようなパイプラインのブロック図となる。

命令レベル並列処理に必要な事項
命令レベル並列処理の方式は、「4. 並列実行の制御」の解決法によって分類される。
VLIW(Very Large Instruction Word)
- 1命令の中に複数の演算を入れたアーキテクチャである
- 命令語長が100ビット以上の長大なものになることから「Very Large Instruction Word」略称VLIWと言われている
同一命令語中のハザードはすべてコンパイラ(または機械語プログラマ)が静的に解決し、命令語の中の演算はすべて同時に実行する
利点
- プロセッサの制御ロジックが簡単(高速)
- 並列化にあたりハザード検出にハードウェアが介在しない
- 問題点
- 透過性・互換性がない
- 機械語プログラムがハードウェアに対して固定されてしまい、互換性がない
- プロセッサの中の演算器の構成によって命令の形式が決まり、構造ハザードから1命令中に可能な演算の組み合わせが決まる
- 静的な並列化の限界
- (解決策)トレーススケジューリング(などの大域的フィールドの最適化)を行う
- 十分に並列化できない場合の命令フィールドの無駄
- (解決策)命令メモリ中では各命令を圧縮して置いておき、キャッシュにコピーするときやデコードするときに本来の姿に戻す
- 透過性・互換性がない
VLIWは、透過性や互換性を犠牲にしてハードウェアを簡単化し、クロックサイクルを短くすることで高速な並列処理を実現する方式である。
スーパスカラ
- 逐次型プログラムを並列実行するアーキテクチャである
- ハードウェアがハザードを検出し、並列可能な命令を選んで並列実行する
- 利点
- 透過性・互換性が維持される
- 問題点
- ハードウェアの複雑化
スーパスカラプロセッサで、2命令同時処理可能なパイプラインの構成図を示す。

大きな変更点としては、命令をデコードする前に、ハザード検出を行う「プリデコーダ」を追加している。
パイプラインの流れは以下となる。
- 命令フェッチ(Instruction Fetch:IF)
- メモリから複数の命令をフェッチする
- 命令プリデコード(Instruction preDecode:ID1)
- フェッチした命令と処理待ちの命令の全ての依存関係を調べ、もし依存関係があれば処理を遅らせる
- 依存関係のない命令を「実行命令レジスタ」に入れる
- 命令ポストデコードとレジスタフェッチ(Instruction Dispatch:ID2)
- 命令実行・アドレス生成(Execution:EX)
- 命令操作の実行
- 分岐の場合、PC書き換え、アドレスの生成を行う
- メモリアクセス(Memory access:MEM)
- データ・メモリ中のオペランドにアクセスする(メモリへの読み書き)
- 書き込み(Write Back:WB)
- メモリからのデータ(結果)をレジスタに書き込む
並列処理とハザード
プリデコードにおけるハザード検出について確認する。
- 構造ハザード
- 並列処理では、ユニット数やポート数が足りないために、構造ハザードが発生する
- 上図では、各ALUごとにデータキャッシュを設けたが、もし2つのALUに対して1つのデータキャッシュしかない場合、データキャッシュは1回に1つしかアクセス要求を受け付けることができない。すなわち、ロード/ストア命令を同時に2つ以上実行することができない。これが典型的な構造ハザードである。
- (解決策)競合する資源を使う命令を、時間をずらして順番に処理する
- データハザード
- 並列する2つの命令の間にはデータ依存関係があってはならない
- プリデコードのステージでデータ依存関係を発見したら、プログラムの中で前に出てくる命令を先に処理し、後の命令は時間をずらして後から処理することになる
- 制御ハザード
- フェッチした命令のどちらかが分岐命令の場合、制御ハザードが起こる可能性がある
- 並列処理をする場合、ストール(ハザードにより命令の実行が止められる状態)の影響は大きくなる
- 遅延分岐はたくさんの共通命令(分岐の有無に関わらず実行する命令)を必要とする
- 分岐予測が外れた場合のペナルティが大きい
まとめ
複数の演算器による並列化に関して、LVIW(Very Large Instruction Word)方式とスーパスカラ方式について理解を深めることができた。
| LVIW | スーパスカラ | |
|---|---|---|
| 透過性・互換性 | × | ○ |
| ハザード検出・並列化 | 静的(コンパイラ) | 動的(H/W) |
| ハードウェア | 簡単 | 複雑 |
| 制御の遅延 | 小 | 大 |
| 命令フィールドの無駄 | 有 | 無 |
")