オペレーティングシステム(OS)UNIX / Linux
MacOS XはFreeBSDベースという話を聞いて、FreeBSDとは?と疑問に思ったので、調べたことを備忘録として残しておく。
オペレーティングシステム(OS)とは
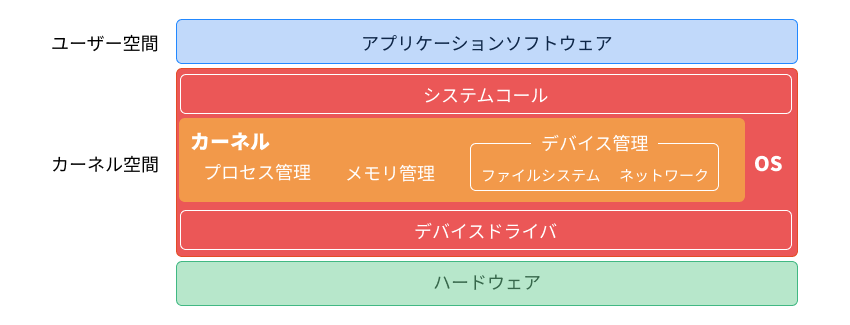
UNIXシステムは、ハードウェア、オペレーティングシステム(Operating System:OS)、アプリケーションソフトウェアの3つの要素で構成されている。
OSは「ハードウェアとアプリケーションソフトウェアを仲介し、システム全体を管理するソフトウェア」である。 OSは中核となるカーネル(Kernel)とそれ以外の部分で構成されている。
UNIXとは
UNIXとは、1969年にアメリカのAT&T社(American Telephone & Telegraph Company)のベル研究所で開発されたOSである。現存する中で最も古いOSの一つであり、様々なOSの土台となっている。
UNIXは以下のような特徴を持つ。
- マルチタスク
- 完全なマルチタスクのOSとして設計されている
- 複数のアプリケーションを同時に利用できる
- マルチユーザー
- 複数のユーザが使用することを前提に設計されている
- 1台のマシンに同時に複数のユーザーがログインできる
- 他のユーザからファイルを守る機能も搭載されている
- コマンドラインインターフェース(CLI)
- 文字列による操作を基本とするUI
- 最近は、X Window Systemによりグラフィカルな環境で利用できる
- 高い安定性
- 他のOSより長い実績を保持しており安全性に定評がある
- あるアプリケーションに異常が発生しても、他のアプリケーションに影響が波及しない
UNIXの種類
UNIX には大きく分けて,AT&T がライセンスを有している System V(ファイブ)系とBSD(Berkeley Software Distribution)系の2種類がある。
System V 系
BSD 系
- UNIXをベースとしたOSのうち、BSD(Berkeley Software Distribution)をもとにして開発されているOSのことを指す。
- 開発元はカリフォルニア大学バークレー校のComputer Systems Research Group (CSRG)である。
- BSDライセンスに準拠。このライセンスはソースコード非公開の商用利用も可能で制約の少ないライセンスである。
- Mac OS X もベースはBSD系のUNIXである。
Linuxとは
LinuxとはUNIXをベースとした無償公開されているオープンソースのOSである。1991年フィンランドのヘルシンキ大学に通う学生であった、リーナス・トーバルズ氏によって開発された。OSSであるため、無償で誰でも利用でき、ソースコードの改良や配布が自由に認められている。そのため、Linuxは世界中のプログラマーが開発に携わる形となり、大きく発展してきた。
Linuxの分類
Linuxのディストリビューション
Linuxのディストリビューションは多く存在する。以下はその代表的なものである。
- RedHat Enterprise Linux(RHEL)
- 開発元:RedHat
- 企業向けのLinuxディストリビューション
- 10年の長期サポートがある
- Fedora
- 開発元:Fedora Project
- Red Hat Linux系のLinuxディストリビューション
- 開発の周期が短く、積極的に先進的な技術が導入されている
- CentOS
- 開発元:CentOS Project
- Red Hat Enterprise Linuxの完全互換を目指していたディストリビューション
- CentOS 8のサポートは2021年12月31日で終了となった
- Ubuntu
- 開発元:Canonical Ltd. / Ubuntu Project
- Debian GNU/Linuxから派生したディストリビューション
- 誰にでも使いやすい最新かつ安定したOSを目標にしている
まとめ
【Linux】ファイルシステム(Ext4)・Macでfuse-ext2によるアクセス
とあるLinuxの組み込みシステムを扱う際に、SDカードが通常と異なり「ext4」であった。ファイルシステムに関して、調べた内容を備忘録として残しておく。
ファイルシステムとは
ファイルシステムとは、OSが提供する機能の一つであり、記憶装置に保存されたデータを管理し、操作するために必要な機能である。
通常OSを操作する上で、データが物理的にどのように格納されているかを意識することなく、ファイルという抽象化されたものを操作することで利用することができる。
ファイルシステムは、ファイルを操作するためのインターフェースを提供する。ファイルを階層構造に格納してラベルをつけ、必要な時にファイルを使えるようにする。
フォーマット(初期化)とは
記憶装置にデータを書き込むためには、まずそのデータを格納するためのスペースが必要となる。そして、空いているスペースにそのままデータを適当に格納した場合、いざ必要な時に取り出すのが大変になってしまう。そのため、データを出し入れしやすくするために、スペースを細かく区切って、番号を設定して格納できるようにする。
OSのファイルシステムに合わせて、記憶領域を区切り、番号を設定することを「フォーマット(初期化)」という。フォーマットで作成する区切りをクラスタという。クラスタはファイルを保存するための最小単位であり、ファイルシステム毎に単位が決まっている。現在使われているファイルシステムでは全て4Kバイト(8セクター)以上が最小単位のクラスターサイズとなっているのが一般的である。
- クラスタ:ファイルの最小単位
- セクタ:データの最小単位(1セクタ=512B, 4KB...)
ファイルシステムの種類
FAT
FAT(File Allocation Table)はMicrosoftが開発したもので、Windowsより前のM S-DOSから採用されているファイルシステム。
- ファイルの位置情報を記録する
-
- 最大ファイルサイズ:2GiB
- 最大ボリュームサイズ:2GiB
- FAT32
- 最大ファイルサイズ:4GiB
- 最大ボリュームサイズ:2TiB
NTFS
NTFS(NT File System)はFATを進化させた、現在のWindowsの主流となっているファイルシステム。
- 業務用OS「Windows NT(N-Ten / New Tecnology)」で導入された
- ファイルの変更履歴などの情報を保存するジャーナリング機能があり、FATよりも高機能で堅牢なシステム
- 圧縮機能、ファイル単位の暗号化機能など
HFS+
HFS+(Hierarchical File System)はHFSの拡張版であり、1998年からMac OS8.1で導入されたシステム。
APFS
APFS(Apple File System)は2016年にAppleが発表した新しいファイルシステム。
XFS
XFS(Extents File System)はUNIX系OSで用いられているファイルシステム。
- 管理領域の一貫性を維持するジャーナリング機能(ファイル管理情報であるメタデータを書き換える際に、一旦ジャーナルと呼ばれる領域に時系列で変更内容を保存してから書き換えを行う)を搭載しているので堅牢性は高い
- (デメリット)一度削除したファイルを復元することができない
ext
ext(extended file system)はLinuxで標準的に利用されるファイルシステム。
- ext1
- 最大ファイルサイズ:64MB
- 実用上はあまり普及していない
- ext2
- 最大ファイルサイズ:4TB
- 最大ボリュームサイズ:16TB
- エラー発生時の整合性チェック(fsck)などに長時間かかる問題あり
- ext3
- ext4
- 最大ファイルサイズ:16TB
- 最大ボリュームサイズ:1EB
- 最大サブディレクトリ数が32000から無制限に改良
VFS(Virtual File System)
Linuxでは全てをファイルとして扱うようになっている。
全ての対象は、データファイルだけではない、HDD、マウスなどの様々なデバイスもファイルとして扱う仕組みになっている。この仕組みを提供するのがVFS(Virtual File System)という仮想的なファイルシステムである。

仮想ファイルシステムはどのようなファイルシステムにも共通して実装されているような、基本的なファイルやディレクトリへのアクセスや操作を行う機能の呼び出し規約(API, Application Programming Interface)を提供する。このためユーザーが実行するプログラムはファイルシステムの差異を意識する必要がなく、統一的なアクセス方法で基本的な操作が可能となる。
LinuxではHDDを複数のパーティションに分割して、それぞれにファイルシステムを作成する。そして、各ファイルシステムをディレクトリツリーのルート(/)以下にマウントすることで利用できるようにする。Linuxのファイルシステムはツリー構造になっており、OSから対象となるハードウェアをソフトウェア的に接続する操作をマウントするという。
LinuxではHDDなどのストレージのハードウェアが認識されても、それだけではファイルシステムとして利用することができない。Linux上ではハードウェアの認識とファイルシステムとしての利用可能であるかは別の問題であり、ファイルシステムとして利用可能にするためには任意であれ、自動であれマウントすることが必要不可欠である。
Mac で SDカード(Ext4)を操作する
利用パッケージ
インストール方法
引用: https://github.com/alperakcan/fuse-ext2#macos
install osxfuse
brew install --cask osxfuse-
vim /tmp/ext4/script.sh#!/bin/sh export PATH=/opt/gnu/bin:$PATH export PKG_CONFIG_PATH=/opt/gnu/lib/pkgconfig:/usr/local/lib/pkgconfig:$PKG_CONFIG_PATH mkdir fuse-ext2.build cd fuse-ext2.build if [ ! -d fuse-ext2 ]; then git clone https://github.com/alperakcan/fuse-ext2.git fi # m4 if [ ! -f m4-1.4.17.tar.gz ]; then curl -O -L http://ftp.gnu.org/gnu/m4/m4-1.4.17.tar.gz fi tar -zxvf m4-1.4.17.tar.gz cd m4-1.4.17 ./configure --prefix=/opt/gnu make -j 16 sudo make install cd ../ # autoconf if [ ! -f autoconf-2.69.tar.gz ]; then curl -O -L http://ftp.gnu.org/gnu/autoconf/autoconf-2.69.tar.gz fi tar -zxvf autoconf-2.69.tar.gz cd autoconf-2.69 ./configure --prefix=/opt/gnu make sudo make install cd ../ # automake if [ ! -f automake-1.15.tar.gz ]; then curl -O -L http://ftp.gnu.org/gnu/automake/automake-1.15.tar.gz fi tar -zxvf automake-1.15.tar.gz cd automake-1.15 ./configure --prefix=/opt/gnu make sudo make install cd ../ # libtool if [ ! -f libtool-2.4.6.tar.gz ]; then curl -O -L http://ftpmirror.gnu.org/libtool/libtool-2.4.6.tar.gz fi tar -zxvf libtool-2.4.6.tar.gz cd libtool-2.4.6 ./configure --prefix=/opt/gnu make sudo make install cd ../ # e2fsprogs if [ ! -f e2fsprogs-1.43.4.tar.gz ]; then curl -O -L https://www.kernel.org/pub/linux/kernel/people/tytso/e2fsprogs/v1.43.4/e2fsprogs-1.43.4.tar.gz fi tar -zxvf e2fsprogs-1.43.4.tar.gz cd e2fsprogs-1.43.4 ./configure --prefix=/opt/gnu --disable-nls make sudo make install sudo make install-libs sudo cp /opt/gnu/lib/pkgconfig/* /usr/local/lib/pkgconfig cd ../ # fuse-ext2 export PATH=/opt/gnu/bin:$PATH export PKG_CONFIG_PATH=/opt/gnu/lib/pkgconfig:/usr/local/lib/pkgconfig:$PKG_CONFIG_PATH cd fuse-ext2 ./autogen.sh CFLAGS="-idirafter/opt/gnu/include -idirafter/usr/local/include/osxfuse/" LDFLAGS="-L/opt/gnu/lib -L/usr/local/lib" ./configure make sudo make install script.shの権限変更
chmod +x /tmp/ext4/script.sh-
/tmp/ext4/script.sh
SDカードをマウントする
- MacにExt4にフォーマットされているSDカードを挿入する
SDカードがどのディスクで認識されているか確認する
$ diskutil list /dev/disk0 (internal, physical): #: TYPE NAME SIZE IDENTIFIER 0: GUID_partition_scheme *2.0 TB disk0 1: EFI EFI 314.6 MB disk0s1 2: Apple_APFS Container disk1 1000.0 GB disk0s2 3: Microsoft Basic Data Linux 300.0 GB disk0s3 4: Microsoft Basic Data BOOTCAMP 700.8 GB disk0s4 /dev/disk1 (synthesized): #: TYPE NAME SIZE IDENTIFIER 0: APFS Container Scheme - +1000.0 GB disk1 Physical Store disk0s2 1: APFS Volume Macintosh HD 15.3 GB disk1s1 2: APFS Snapshot com.apple.os.update-... 15.3 GB disk1s1s1 3: APFS Volume Macintosh HD - Data 61.6 GB disk1s2 4: APFS Volume Preboot 328.5 MB disk1s3 5: APFS Volume Recovery 622.1 MB disk1s4 6: APFS Volume VM 20.5 KB disk1s5 /dev/disk2 (external, physical): #: TYPE NAME SIZE IDENTIFIER 0: FDisk_partition_scheme *15.7 GB disk2 1: Windows_FAT_32 15.6 GB disk2s1disk0とdisk1は、Macの内部なので、externalであるdisk2がSDカードであることがわかる。
Windows_FAT_32であるdisk2s1をマウントすることで、SDカードの中にアクセスすることができる。SDカードをマウントしたいフォルダをDesktopに作成する
mkdir ~/Desktop/ext4SDカードをマウントする
sudo mount -t fuse-ext2 /dev/disk2s1 /User/<-username->/Desktop/ext4デスクトップに以下のようなフォルダが表示される。

内部を確認することで、SDカードの中身を確認することができる。
SDカードをアンマウントする
開いているフォルダなどは全て閉じて、以下を実行する。
sudo umount /User/<-username->/Desktop/ext4
フォルダを開いていたり、フォルダにアクセスしていると、以下のエラーが出る。
$ sudo umount /Users/yuki.seri/Desktop/ext4 umount(/Users/yuki.seri/Desktop/ext4): Resource busy -- try 'diskutil unmount'
(おまけ)ext4fuse
ext4fuse はRead-Onlyで書き込みができない。それでも良ければ、使ってみてください。
インストール
brew install ext4fuseするとError: ext4fuse has been disabled because it requires FUSE!となったので、以下で対応してインストール実施。
brew install --cask osxfuse brew install --formula --build-from-source ./ext4fuse.rb
マウント/アンマウント
# マウント sudo ext4fuse /dev/disk2s1 /path_to_your_mountpoint -o allow_other # アンマウント sudo umount /path_to_your_mountpoint
まとめ
ファイルシステムに関して、知識を整理することができた。MacでもLinuxのExt4のファイルシステムを操作ができるようになった。
【Rails】devise_token_authでToken認証を実装する
結構前にやったことであるが、Rails6でAPIを作成した際に、認証機能を簡単に実装できるdevise_token_authを使ってToken認証機能を実装したので備忘録として残しておく。
実行環境
- Ruby : 3.0.1
- Ruby on Rails : 6.1.5
- devise_token_auth : 1.2.0
- rack-cors : 1.1.1
Sampleコードもおいているので、試したい方いましたらご自由にどうぞ。
インストール
Gemfileに devise_token_auth を追加して、bundle install を実行する
# For Add Access-Token gem 'devise_token_auth'
deviceのUserモデルを作成する前に、deviceをインストールしていないと、rails db:migrate時に以下のような「Userモデルに対するdeviseメソッドが定義されていない」というエラーが出てしまう。
/usr/local/bundle/gems/activerecord-6.1.5/lib/active_record/dynamic_matchers.rb:22:in `method_missing': undefined method `devise' for User:Class (NoMethodError)
そのため、先にdeviceをインストールしてから、authのUserモデルを作成するようにする。
bash-5.1# bundle exec rails g devise:install
// ~省略~
bash-5.1# bundle exec rails g devise_token_auth:install User auth
Running via Spring preloader in process 90
create config/initializers/devise_token_auth.rb
insert app/controllers/application_controller.rb
gsub config/routes.rb
create db/migrate/20220422074222_devise_token_auth_create_users.rb
create app/models/user.rb
一部不要なUserのカラムを削除して、bundle exec rails db:migrateを実行してDBのテーブルを作成する。
class DeviseTokenAuthCreateUsers < ActiveRecord::Migration[6.1] def change create_table(:users) do |t| ## Required t.string :provider, :null => false, :default => "email" t.string :uid, :null => false, :default => "" ## Database authenticatable t.string :encrypted_password, :null => false, :default => "" ## Recoverable t.string :reset_password_token t.datetime :reset_password_sent_at t.boolean :allow_password_change, :default => false ## Rememberable t.datetime :remember_created_at ## Confirmable t.string :confirmation_token t.datetime :confirmed_at t.datetime :confirmation_sent_at t.string :unconfirmed_email # Only if using reconfirmable ## Lockable # t.integer :failed_attempts, :default => 0, :null => false # Only if lock strategy is :failed_attempts # t.string :unlock_token # Only if unlock strategy is :email or :both # t.datetime :locked_at ## User Info t.string :name t.string :email ## Tokens t.text :tokens t.timestamps end add_index :users, :email, unique: true add_index :users, [:uid, :provider], unique: true add_index :users, :reset_password_token, unique: true add_index :users, :confirmation_token, unique: true # add_index :users, :unlock_token, unique: true end end
devise_token_auth設定
設定に関しては、以下を採用することにする。
DeviseTokenAuth.setup do |config| # By default the authorization headers will change after each request. The client is responsible for keeping track of the changing tokens. Change this to false to prevent the Authorization header from changing after each request. config.change_headers_on_each_request = false # By default, users will need to re-authenticate after 2 weeks. This setting determines how long tokens will remain valid after they are issued. config.token_lifespan = 2.weeks
CORS対応
APIとクライアントが異なるドメインに存在する場合は、クロスオリジンリクエストを許可するようにRailsAPIを構成する必要がある。CORS(Cross-Origin Resource Sharing)を実現するために、rack-corsのgemを利用する。以下をGemfileに追加して、bundle installを実行する。
gem 'rack-cors'
以下を設定ファイルに追記する。(ただし、任意のドメインからのクロスドメインリクエストが許可されるため、必要なドメインのみをホワイトリストとして設定するほうがセキュリティ的に安全である。)
module App class Application < Rails::Application # ~省略~ # CORS config.middleware.insert_before 0, Rack::Cors do allow do origins '*' resource '*', :headers => :any, :expose => ['access-token', 'expiry', 'token-type', 'uid', 'client'], :methods => [:get, :post, :options, :delete, :put] end end end end
User作成
初回のUserに関しては、seedで流し込む。
# API-user User.create!( name: 'test-user1', email: 'test-user1@test.com', password: 'password1' )
bundle exec rails db:seedでsampleユーザーを作成する。
routes設定
ルーティングに関しては、今回APIとして /api/v1 を先頭につけることにする。そのため、namespaceを用いてルーティングを作成する。
Rails.application.routes.draw do root 'home#index' namespace :api do namespace :v1 do get '/whoami', to: 'tests#whoami' # device_token_auth mount_devise_token_auth_for 'User', at: 'auth' end end end
authに関するルーティングは、mount_devise_token_auth_for 'User', at: 'auth'で自動生成される。
bash-5.1# bundle exec rails routes | grep auth
new_api_v1_user_session GET /api/v1/auth/sign_in(.:format) devise_token_auth/sessions#new
api_v1_user_session POST /api/v1/auth/sign_in(.:format) devise_token_auth/sessions#create
destroy_api_v1_user_session DELETE /api/v1/auth/sign_out(.:format) devise_token_auth/sessions#destroy
new_api_v1_user_password GET /api/v1/auth/password/new(.:format) devise_token_auth/passwords#new
edit_api_v1_user_password GET /api/v1/auth/password/edit(.:format) devise_token_auth/passwords#edit
api_v1_user_password PATCH /api/v1/auth/password(.:format) devise_token_auth/passwords#update
PUT /api/v1/auth/password(.:format) devise_token_auth/passwords#update
POST /api/v1/auth/password(.:format) devise_token_auth/passwords#create
cancel_api_v1_user_registration GET /api/v1/auth/cancel(.:format) devise_token_auth/registrations#cancel
new_api_v1_user_registration GET /api/v1/auth/sign_up(.:format) devise_token_auth/registrations#new
edit_api_v1_user_registration GET /api/v1/auth/edit(.:format) devise_token_auth/registrations#edit
api_v1_user_registration PATCH /api/v1/auth(.:format) devise_token_auth/registrations#update
PUT /api/v1/auth(.:format) devise_token_auth/registrations#update
DELETE /api/v1/auth(.:format) devise_token_auth/registrations#destroy
POST /api/v1/auth(.:format) devise_token_auth/registrations#create
api_v1_auth_validate_token GET /api/v1/auth/validate_token(.:format) devise_token_auth/token_validations#validate_token
上記より、以下を用いることにする。
- sign_up :
POST /api/v1/authorGET /api/v1/auth/sign_up - sign_in :
POST /api/v1/auth/sign_in - sign_out :
DELETE /api/v1/auth/sign_out
(おまけ)namespace, scope, moduleの違い
それぞれの使い分けは、URL PathとController Pathの変更の影響範囲によって異なる。
| URL Path | Controller Path | |
|---|---|---|
| scope | 変更される | 変更しない |
| namespace | 変更される | 変更される |
| module | 変更しない | 変更される |
controller設定
通常devise_token_authでは、sign-inのリクエストを送信したレスポンスHeaderにあるaccess-token, client, uidを毎回リクエストヘッダに追加することで、認証することができる。( RFC 6750 Bearer Token に準拠している。)
before_action :authenticate_user!, unless: :devise_controller?
このメソッドをcontrollerに追加することで、actionを実行する前にまず認証情報を確認する。ただし、毎回access-token, client, uidの3つをヘッダーに追加するのは面倒である。そこで、Authorizationヘッダーを用いた認証に変更したいと思った。
Bearer認証を満たすには以下の実装をする必要があった。
- Authorization: Bearer
のリクエストに認証する - tokenは任意の token68 文字列とする
- レスポンスヘッダーに、WWW-Authenticate: を追加する
- 200 OKの場合、WWW-Authenticate: Bearer realm=""
- 401 Unauthorizedの場合、WWW-Authenticate: Bearer realm="token_required"
- 400 Bad Requestの場合、WWW-Authenticate: Bearer error="invalid_request"
- 401 Unauthorizedの場合、WWW-Authenticate: Bearer error="invalid_token"
- 403 Forbiddenの場合、WWW-Authenticate: Bearer error="insufficient_scope"
まず、sign_in時のレスポンスを変更する。routesで一部controllerに変更を加える設定を追加する。sign_in時には、devise_token_auth/sessions#createのactionが動いているので、sessionsのcreateのみに変更を加える。
# device_token_auth mount_devise_token_auth_for 'User', at: 'auth', controllers: { sessions: 'custom/sessions', }
実際に変更する内容は、以下の通りである。
- ヘッダーにaccess-tokenが含まれていれば、
access-token,client,uidのjsonデータからBase64文字列のtokenを生成する - Headerから認証情報を確認するのは面倒なので、Bodyのjsonデータにtokenと期限を追加する
class Custom::SessionsController < DeviseTokenAuth::SessionsController prepend_after_action :join_tokens, only: [:create] private def join_tokens return if response.headers['access-token'].nil? auth_json = { 'access-token' => response.headers['access-token'], 'client' => response.headers['client'], 'uid' => response.headers['uid'], } response.headers.delete_if{|key| auth_json.include? key} access_token = CGI.escape(Base64.encode64(JSON.dump(auth_json))) json_body = JSON.parse(response.body) new_json_body = { 'user' => json_body['data'], 'access_token' => access_token, 'expiry' => response.headers['expiry'] } response.body = JSON.dump(new_json_body) end end
こうすることで、sign_in時には以下のようなレスポンスとなる。
{ "user": { "email": "test-user1@test.com", "uid": "test-user1@test.com", "id": 1, "provider": "email", "allow_password_change": false, "name": "test-user1" }, "access_token": "eyJhY2Nlc3MtdG9rZW4iOiJsZkNqTmhxRDg3Q0hQSGhNMnQ0SXVBIiwiY2xp%0AZW50IjoicGhqeVVfZjdXS1pqN2otWTV6a3VtdyIsInVpZCI6InRlc3QtdXNl%0AcjFAdGVzdC5jb20ifQ%3D%3D%0A", "expiry": "1651998480" }
次に、取得したtokenをAuthorizationヘッダーに追加してAPIをコールする。
devise_token_authではaccess-token, client, uidで認証するので、認証する前に、サーバーサイド側でtokenをaccess-token, client, uidに分離する処理を追加する。
class Api::BaseController < ApplicationController before_action :split_tokens before_action :authenticate_api_v1_user!, unless: :devise_controller? private def split_tokens return if request.headers['Authorization'].nil? token = JSON.parse(Base64.decode64(CGI.unescape(request.headers['Authorization'].match(/Bearer /).post_match))) request.headers['access-token'] = token['access-token'] request.headers['client'] = token['client'] request.headers['uid'] = token['uid'] end end
これで、Authorizationヘッダーを追加することで認証ができるようになった。ヘッダーに付加すべき情報をまとめることができて、処理が楽になった。
class Api::V1::TestsController < Api::BaseController def whoami render json: current_api_v1_user, status: :ok end end
http://localhost:3000/api/v1/whoami にリクエストを送信し、Authorizationヘッダーが正常であればユーザー情報を取得することができ、認証できない場合にはエラーが返却される。
まとめ
devise_token_authでRailsAPIのToken認証を実装することができた。
ただし、WWW-Authenticateをレスポンスヘッダーに付加できていないので、まだBearer認証の実装を満たすことができていない。また、今回正常系の確認しかできておらず、異常系、エラーハンドリングの実装ができていないので、引き続き実装を進めていきたい。
【Arduino】ウォッチドッグタイマー(WDT)
Arduino Unoで死活監視のために、ウォッチドッグタイマー(WDT)を実装したので備忘録として残しておく。
ウォッチドッグタイマー(WDT)とは
ウォッチドッグタイマー(Watchdog Timer:WDT)はマイコンのプログラムが暴走・停止していないかを監視するタイマーである。具体的には、一定時間を経過しても応答がない場合にシステムをリセットする機能である。
ウォッチドッグ(Watchdog)は英語で「番犬」という意味であり、マイコンを見張る役割を果たす。

上記の図では、外付けのWDTを想定している。実際にはMCUの異常を検知するWDT機能はMCU自体にも搭載されている。ただし、その場合にはMCU自体が異常を起こすと、WDT機能が正常に働かない可能性がある。そのため、MCU以外に外付けのWDTを設置して、WDT機能を独立させておくことでシステムの安全性を高めることができる。
ATmega328P
Arduino Unoには、ATmega328Pのマイコンが搭載されている。
ATmega328Pのデータシートを確認すると、「10.8 Watchdog Timer」に詳細な仕様が記載されている。
MCUSRレジスタとWDTCSRレジスタを操作することにより、WDT機能を実現している。
MCUSR(MCU Status Register)
[ - ][ - ][ - ][ - ][WDRF][BORF][EXTRF][PORF]
- WDRF:Watchdog System Reset Flag
- BORF:Brown-out Reset Flag
- EXTRF:External Reset Flag
- PORF:Power-on Reset Flag
WDTCSR(Watchdog Timer Control Register)
[WDIF][WDIE][WDP3][WDCE][WDE][WDP2][WDP1][WDP0]
- WDIF:Watchdog Interrupt Flag
- WDIE:Watchdog Interrupt Enable ウォッチドッグ・割込み許可
- WDCE:Watchdog Change Enable ウォッチドッグ変更許可 設定を変更する場合に、HIGHにする必要がある。4クロック後にクリアされる。
- WDE:Watchdog System Reset Enable ウォッチドッグ・システム・リセット許可
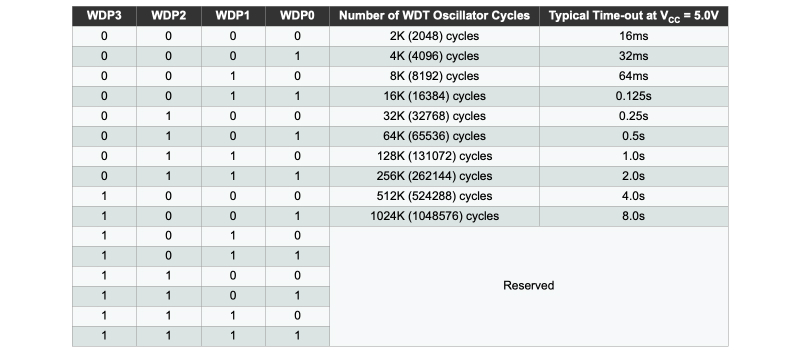
- WDP3..0: Watchdog Timer Prescale Select ウォッチドッグ・タイマー分周比
avr/wdt.h ライブラリ
avr/wdt.hというライブラリをインクルードして使用する。
- wdt_reset() : WDTの設定をリセットするための関数
- wdt_enable(value) : WDTを有効にする関数(valueに定数を入れて時間を設定する)
- wdt_disable() : WDTを無効にする関数
実装例
回路図

- MCUのWDTを利用する
- リセットするまでの間隔は、4sとする
- D13をWDT-OUTとする
- D12をWDT-INとする
- 10msごとにloop処理を行い、WDT-OUTをHIGHにして、WDT-INでHIGH信号を受け取れたら、WDT_Reset_Counterをインクリメントする(+1する)
- WDT_Reset_Counterが200になれば、
wdt_reset()を実行する- 10ms x 200 = 2000ms(2s)
- すなわち、リセット時間の半分の約2sごとにMCUにリセット信号を送る
- 2sごとにリセット信号を送信できない場合、WDTのリセット時間4sを経過してしまい、リセット処理が実行される
#include <avr/wdt.h> int WDTOUT = 13, WDTIN = 12; int WDT_Count_Pin, WDT_Reset_Counter, WDT_Reset_Time = 200; void setup() { Serial.begin(9600); pinMode(WDTIN, INPUT); pinMode(WDTOUT, OUTPUT); wdt_reset(); wdt_enable(WDTO_4S); Serial.println("WDTstarted"); } void loop() { digitalWrite(WDTOUT, HIGH); WDT_Count_Pin = digitalRead(WDTIN); if(WDT_Count_Pin == 1) { WDT_Reset_Counter = WDT_Reset_Counter + 1; Serial.println(WDT_Reset_Counter); }; if(WDT_Reset_Counter == WDT_Reset_Time) { WDT_Reset_Counter = 0; Serial.print("WDT_NORMAL"); wdt_reset(); }; digitalWrite(WDTOUT, LOW); delay(10); }
まとめ
Arduinoで無事にWDT機能を実現することができた。 意外に簡単に実装できて、嬉しい限りであった。
仮想記憶(仮想メモリ)
現在、CSの勉強のために、コンピュータアーキテクチャ (電子情報通信レクチャーシリーズ)を読んでいる。
前回は、キャッシュメモリに焦点を当てた。今回は、仮想記憶についてまとめていく。
仮想記憶(仮想メモリ)とは
仮想記憶(仮想メモリ)は、物理上のメモリである主記憶装置(RAM)だけでなく、ハードディスクなどの補助記憶装置を組み合わせることで、主記憶装置(RAM)の容量を、命令語に入っているアドレスの許す限りの大きさに拡張する手法である。
- なぜ拡張する必要があるのか
- コンピュータ上に入っている物理上のメモリ(RAM)だけでは容量が足りず、プログラムを実行することができない。
- 拡張する手法?
- メインメモリやキャッシュメモリのように、仮想記憶(仮想メモリ)を「記憶装置」のような表現にしているが、記憶装置ではなく、実質的にユーザーにとってメインメモリの容量を拡張するテクニック(手法)である。
- 「実質的に」が意味するところは、キャッシュメモリ同様に、仮想記憶の主記憶と補助記憶を「巨大な主記憶」として使えるように透過性を持たせている。
- キャッシュメモリ管理はハードウェアによって行われていたが、仮想記憶(メモリ)管理はオペレーティングシステム(OS)によって行われる。
- 命令語に入っているアドレスの許す限りの大きさとは
- 仮想記憶の導入メリット
- 主記憶よりも大きな容量のメモリがあるものとしてプログラムを書くことができる
- メモリ領域の保護
- 複数のプログラムが互いのデータを読み書きする場合、意図的か否かを問わず相互干渉できないようにするための一連の機構。
- 複数のプログラムが1つの物理記憶を共有して安全に分かち合って使えるようになる
仮想記憶の構成

仮想記憶とキャッシュの概念は基本的には同じである。しかし、両者の歴史的背景から異なった用語が使用されている。
- 仮想記憶のブロック:ページ
- 仮想記憶のミス:ページフォールト
仮想記憶を使用する場合、CPUによって仮想アドレスが生成される。この仮想アドレスが、ハードウェアとソフトウェアの連携によって物理アドレスに変換される。物理アドレスに基づいて、実際に主記憶装置へのアクセスが行われる。仮想記憶と物理メモリのアドレス対応付けの過程をアドレス・マッピング、またアドレス変換と呼ぶ。
プロセスを作成するときに、そのプロセスの全てのページ用の領域をフラッシュ・メモリまたはディスク上に取る。このディスク領域をスワップ領域と呼ぶ。同時に、OSは各仮想ページがディスク上のどこに格納されているかを記録するデータ構造を主記憶上に作成する。このデータ構造をページテーブルと呼ぶ。
物理メモリ上に空き領域を作り出すために、あるメモリ領域の記憶内容をストレージ上のスワップ領域に書き出して抹消する操作のことをページアウト(スワップアウト)と呼ぶ。
反対に、ストレージ上に退避した内容へのアクセス要求があり、物理メモリ上の領域に書き戻してアクセス可能にする操作のことをページイン(スワップイン)と呼ぶ。
仮想記憶システムの設計を左右する要因はページフォールトが発生した時の処理コストの高さである。ディスク上での1件のページフォールトの処理に要するクロック・サイクル数は何百万にも及ぶ。この膨大なミス・ペナルティに対処する必要がある。
ページテーブルによるアドレス変換
仮想記憶において、ミスの発生件数を出来るだけ減らすために、競合性ミスが発生しないフルアソシアティブ形を用いる。ただし、キャッシュでやった全エントリのタグ比較による連想処理は現実的ではない。仮想記憶では、ページテーブルを用いて、仮想アドレスのページ番号をインデックスとして、対応する物理ページの所在を突き止める。
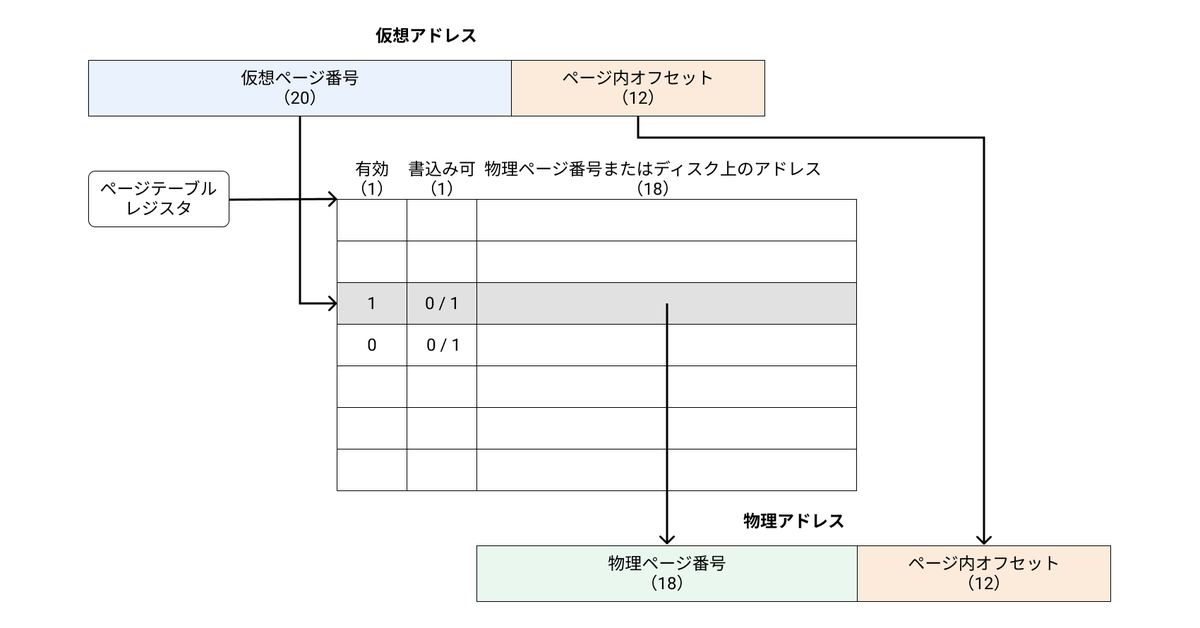
仮想アドレスは、仮想ページ番号とページ内オフセットからなる。ページ内オフセットは、仮想アドレスと物理アドレスで共通である。
各プログラムごとにページテーブルが用意され、それを通じてプログラムの仮想アドレス空間が物理メモリにマッピングされる。メモリ中のページテーブルの所在位置を示すために、ページテーブルの始点を指すレジスタ、ページテーブルレジスタをハードウェアに用意する。
ページテーブルの各エントリには、有効ビット、書込み可能ビットなどの制御フラグビットと、物理ページ番号またはディスク上のアドレスが格納されている。有効ビットがオンの場合に、このエントリの物理ページ番号が有効となり、ページ内オフセットと組み合わせて物理アドレスが求められる。
上図では、仮想アドレスを32ビット、ページサイズを4KB、物理アドレスを30ビットと仮定している。ページサイズが4KBなので、ページ内にあるアドレスは全部で4KB、すなわち 212 バイトとなる。212 バイトあれば、ページ内のアドレスを全て表現できるので、ページ内オフセットは12bitとなる。よって、仮想ページ番号は32 - 12 = 20bitとなる。
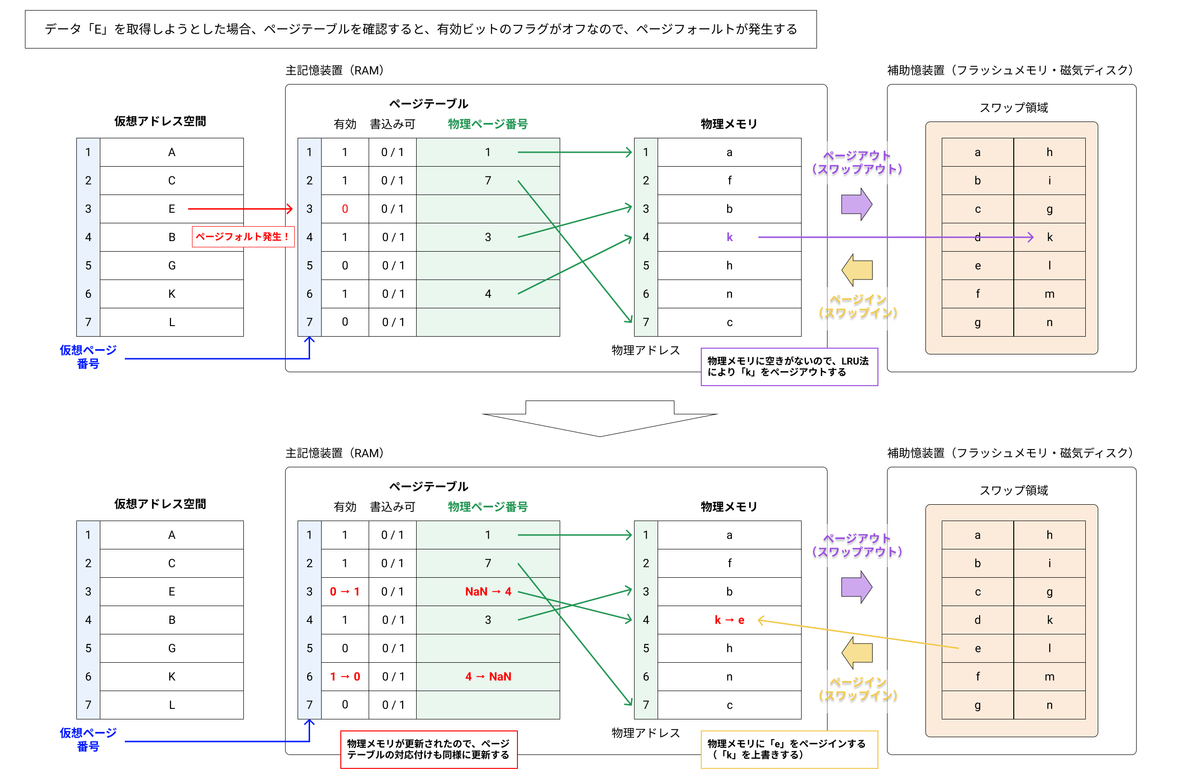
ページフォールト
仮想ページの有効ビットがオフであると、そのページにアクセスされた時にページフォールトが発生する。ページフォールトは、MMU(Memory Management Unit)により検知される。
- MMUがページフォールトを検知し、例外処理の割り込みが発生する(CPUの処理を中断する)
- OSに制御が移され、OSは特権的な命令を用いて以下の処理を実行する
- 物理メモリ中のページが全て使用されている場合、近い将来に使用される可能性が最も低いと思われるページをディスク上のスワップ領域に書き込む。(ページアウト)
- LRU(Least Recently Used)法
- 過去最も参照されていないページを置き換える
- 厳密に実現しようとするとコストが高くなる
- OSでは、近似的なLRU法が用いられる(使用ビット、参照ビットを用意し、ページにアクセスされるたびにフラグをセットする。OSはこの使用ビットを定期的にクリアし、ある期間にどのページがアクセスされたかを判定できるようにする。)
- LRU(Least Recently Used)法
- ページテーブルのエントリに入っている物理ページ番号から、ディスクの中から該当するページを探し出し、そのページを物理メモリに書き込む。(ページイン)
- 物理メモリのデータが書き換わったので、ページテーブルを更新する
- ページアウトで物理メモリからスワップ領域に書き出したページの有効ビットのフラグをオフにする
- ページインで物理メモリに書き込んだページの物理ページ番号を書き込み、有効ビットのフラグをオンにする
- 物理メモリ中のページが全て使用されている場合、近い将来に使用される可能性が最も低いと思われるページをディスク上のスワップ領域に書き込む。(ページアウト)
上記の流れの一例を示す。
書込みはライト・バック方式
キャッシュへのアクセス時間と主記憶へのアクセス時間の差は数十〜数百クロック・サイクルである。したがって、書き込みにはライト・スルー方式を採用できる。ただし、書き込みにかかる時間をプロセッサに対して隠すために、書き込みバッファを使用する必要がある。
仮想記憶システムでは、補助記憶装置への書き込みには数百万クロック・サイクルを要することがありえる。そのため、書き込みバッファを利用してディスクへも同時に書き込みを行うライト・スルー方式は非現実的である。仮想記憶システムでは、ライト・バック方式を取らざるをえない。ライト・バック方式では、個々の書き込みはページに対してだけ行われる。そして、メモリ内のページが置き換え対象になったときに、ページをディスクにコピーして戻す。
書き戻し操作には高いコストがかかる。そのため、ページを置き換えるときに、そのページを書き戻す必要があるかどうかを判定できるように、ページテーブルにダーティビット(dirty bit)を追加する。ページに何らかの書き込む時には、このダーティビットのフラグも同時にセットする。ダーティビットのフラグが立っているページをダーティ・ページと呼ぶ。
アドレス変換の高速化:TLB
ページ・テーブルは主記憶装置に格納されるので、各メモリ・アクセスには最低でも2倍の時間が必要になる。
アクセスの性能を改善する鍵は、ページテーブルを参照する際の局所性にある。ある仮想ページ番号の変換が行われると、同じ変換が近いうちに再び行われる可能性が高い。なぜならば、そのページ上の語の参照には時間的および空間的局所性があるからである。
そのため、現代のプロセッサには最近行われたアドレス変換の内容を一時的に保存しておく専用のキャッシュが備えられている。この特別なアドレス変換キャッシュはアドレス変換バッファ(TLB:Translation Lookaside Buffer)と呼ばれる。
TLBはフルアソシアティブのキャッシュであり、タグの大きさは仮想ページ番号の大きさとなる。ページテーブルを参照する代わりにTLBにアクセスするので、TLBには参照ビットやダーティビットのような制御ビットも含める必要がある。また、TLBは命令用とデータ用の2種類を持つのが一般的である。
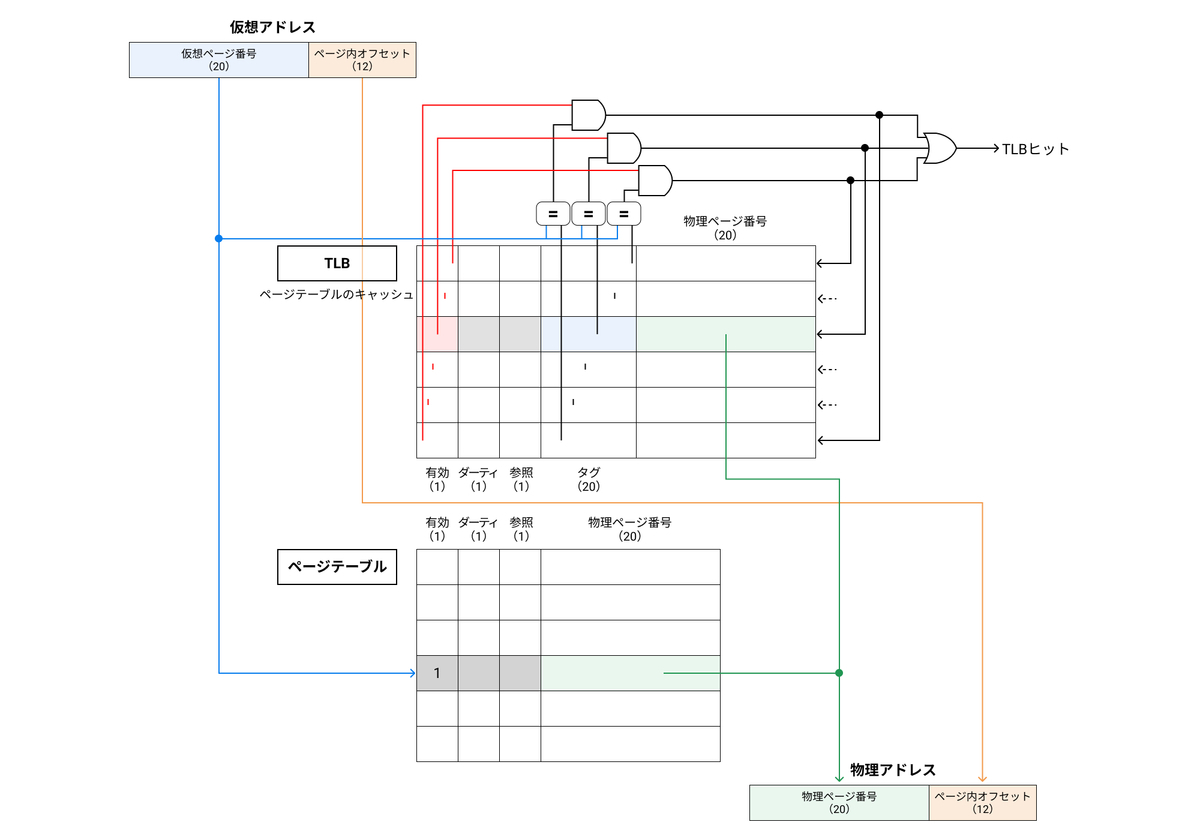
TLBの動作は以下のようになる。
- メモリアクセスが起こると、仮想ページ番号をタグとして、TLBが参照される
- TLBがヒットすると、該当する物理ページ番号が取り出され、ページ内オフセットと合わせて物理アドレスが作られる
- TLBがミスすると、ページテーブルが参照され、TLBの空いているエントリに現在参照している仮想ページ番号に対応する物理ページ番号が入れられる。TLBが空いていない場合、LRUなどのやり方でエントリが一つ空けられる。
仮想アドレスから物理アドレスを求めるときには、TLBミス、ページフォールトの二つの例外が発生する可能性がある。
- TLBミス
- TLBのエントリを一つ空けてページテーブルから対象となる物理ページ番号を書き込む
- ページフォールト
- 主記憶上に物理ページを確保し、補助記憶装置からページを読み出し、ページテーブルを更新する
- 更に、TLBのエントリを一つ空けて、対象となる物理ページ番号を書き込む
キャッシュと仮想記憶
仮想記憶とキャッシュの両方を用いたメモリアクセス機構について整理を行う。キャッシュアクセスとTLB参照を並列化することで、語の読み書きの時間を短縮することができる。キャッシュとTLBのアクセス時間を短くし、キャッシュミス、TLBミス、ページフォールトが起こる確率を出来るだけ低く抑えることが設計上重要となる。キャッシュと仮想記憶の組み合わせには、大きく分けて以下の3種類がある。
- 直列形物理アドレスキャッシュ
- TLBで物理アドレスを生成し、そのアドレスを用いてキャッシュにアクセスする。
- メリット
- 直列形で順番に実行するため、メモリ後にアクセスするまでに時間がかかってしまい、遅い
- デメリット
- キャッシュサイズやアドレスに制約がない
- 並列形物理アドレスキャッシュ
- TLBで物理ページ番号を生成すると同時に、ページ内オフセットを用いてキャッシュにアクセスする。TLBから生成された物理ページ番号とキャッシュのタグを照合し、等しければキャッシュラインが求めるものとなる。
- メリット
- TLBとキャッシュに並列アクセスするので、早い
- デメリット
- キャッシュインデックスが仮想アドレスの”ページ内オフセット”の大きさで決まってしまうため、キャッシュサイズが限定されてしまう。
- 仮想アドレスキャッシュ
- 仮想アドレスを用いてキャッシュにアクセスする。上記の2つと異なり、物理アドレスに変換されていない仮想アドレスを用いて、キャッシュにアクセスするので、TLBのクリティカル・パスが外れ、キャッシュのレイテンシが減少する。
- ただし、キャッシュミスが発生した場合、主記憶からデータを読み出してキャッシュに入れるためには、仮想アドレスを物理アドレスに変換しておく必要がある。
- 仮想アドレスを用いてキャッシュにアクセスした場合、複数のプロセスで共有されているページがあると、各プログラムでの共有ページの仮想アドレスが異なっているためにエイリアスが発生する可能性がある。エイリアスは、同一オブジェクトが複数の名前(アドレス)を持つ時に発生する。この時、一方のプログラムがデータを書き込んだにも関わらず、他方のプログラムはそのデータが変更されたことがわからない、という事態が発生してしまう。そのため、エイリアスが発生しないような制約を追加する必要がある。
- メリット
- TLBとキャッシュに並列アクセスするので、早い
- 仮想アドレスそのもので、キャッシュにアクセスするので容量制限もない
- デメリット
- エイリアスの問題が発生する

まとめ
仮想メモリに関して、知識を整理をすることができた。
キャッシュと仮想メモリの違い
- キャッシュ
- CPUのデータアクセス速度を高速化する、高速小容量の記憶装置
- 直近で使用されたデータのコピーを格納する
- メモリ管理は、ハードウェアによって行われる
- 仮想メモリ
- メインメモリの容量を拡張するテクニック(手法)
- メインメモリよりも大きいプログラムの実行を可能とする
- メモリ管理は、OSによって行われる
")
